



OpenSearch Ingestion 是一种完全托管的无服务器数据收集器,可将实时日志、指标和跟踪数据传送到Amazon OpenSearch Service域和Amazon OpenSearch Serverless集合。在这篇文章中,我们将解释如何使用 Terraform 部署 OpenSearch 摄取管道。例如,我们使用 HTTP 源作为输入,使用Amazon OpenSearch Service域(索引)作为输出。
解决方案概述
本文中的步骤使用 Terraform 部署可公开访问的 OpenSearch 摄取管道,以及该管道将数据摄取到 Amazon OpenSearch 所需的其他支持资源。我们已经使用 Terraform 实施了教程:使用 Amazon OpenSearch Ingestion 将数据引入域。
我们使用 Terraform 创建以下资源:
Amazon OpenSearch 域(可公开访问的域)
OpenSearch 提取管道的AWS Identity and Access Management (IAM) 角色
Amazon CloudWatch日志组
OpenSearch 摄取管道
您创建的管道公开 HTTP 源作为输入,并公开 Amazon OpenSearch 接收器以保存批量事件。
先决条件
要按照本文中的步骤操作,您需要满足以下条件:
一个活跃的 AWS 账户。
Terraform 安装在您的本地计算机上。有关更多信息,请参阅安装 Terraform。
使用 Terraform 创建 AWS 资源所需的必要 IAM 权限。
awscurl 用于使用AWS Sigv4身份验证通过命令行发送 HTTPS 请求。有关安装此工具的说明,请参阅GitHub 存储库。
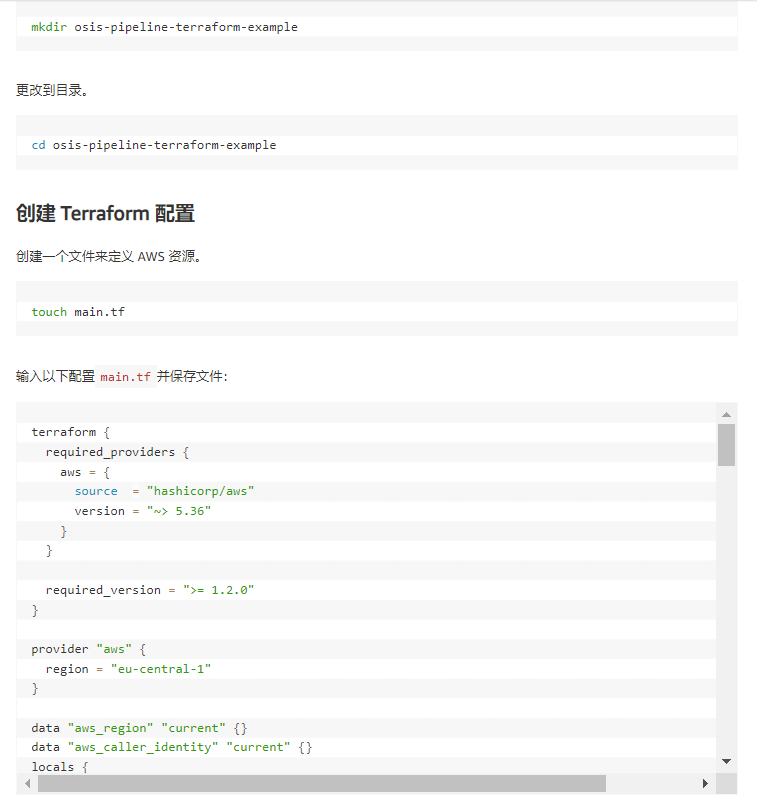
创建目录
在 Terraform 中,基础设施作为代码进行管理,称为项目。Terraform 项目包含各种 Terraform 配置文件,例如main.tf、provider.tf、variables.tf和output.df 。让我们在服务器或计算机上创建一个目录,可用于通过AWS 命令行界面(AWS CLI) 连接到 AWS 服务:
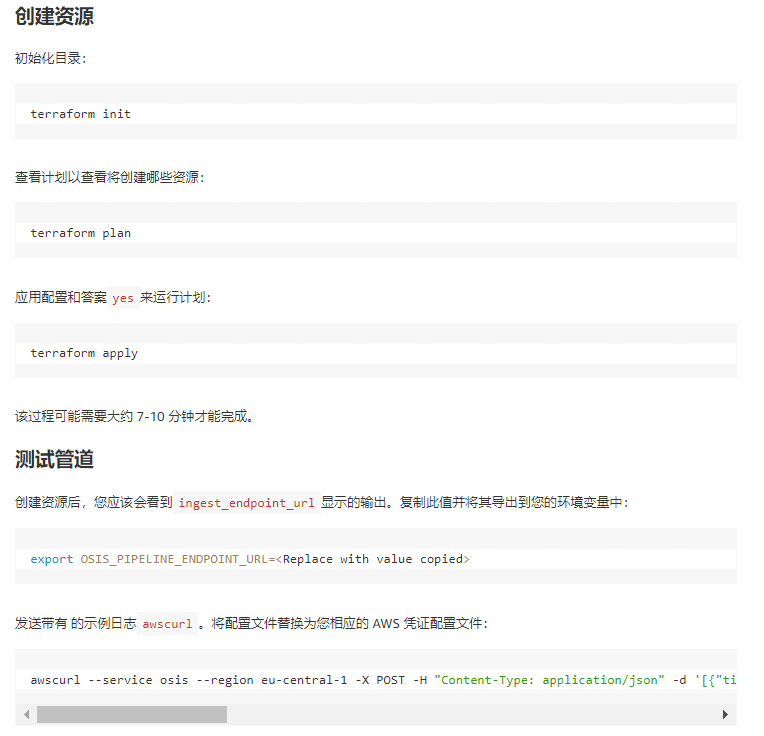
您应该收到一封200 OK回复。
要验证数据是否已在 OpenSearch 摄取管道中摄取并保存在 OpenSearch 中,请导航到 OpenSearch 并获取其域端点。替换<OPENSEARCH ENDPOINT URL>下面给出的代码片段中的 并运行它。

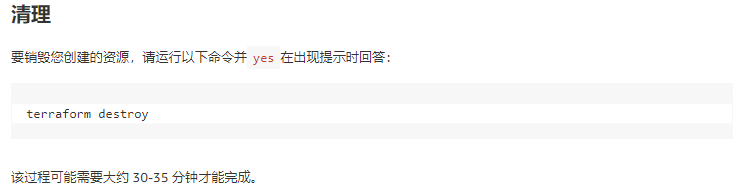
结论
在这篇文章中,我们展示了如何使用 Terraform 部署 OpenSearch 摄取管道。AWS 提供了各种资源,供您快速开始使用 OpenSearch Ingestion 构建管道并使用 Terraform 来部署它们。您可以使用各种内置管道集成来快速从Amazon DynamoDB、Amazon Managed Streaming for Apache Kafka (Amazon MSK)、Amazon Security Lake、Fluent Bit 等中提取数据。以下 OpenSearch 摄取蓝图允许您以最少的配置更改构建数据管道,并使用 Terraform 轻松管理它们。要了解更多信息,请查看Amazon OpenSearch 摄取的Terraform 文档。
原文链接;https://aws.amazon.com/cn/blogs/big-data/introducing-terraform-support-for-amazon-opensearch-ingestion/


