



出门问问发布第七代TTS引擎 TicVoice 7.0
全新语音编码范式与极致用户体验

出门问问(02438.HK)联合香港科技大学、上海交通大学等研究机构,共同开源新一代语音生成模型 Spark-TTS。该模型已发布于开源社区 SparkAudio,迅速登上 Hugging Face 趋势榜 TTS 第二名。
TicVoice 7.0 是出门问问推出的商业化高品质 TTS 引擎,目前已应用于旗下 AI 配音产品「魔音工坊」。其核心功能包括 3秒语音克隆能力及卓越的精品发音人定制效果,适用于智能客服、有声书演绎、情感直播、影视解说和配音等场景。
TicVoice 7.0 作为出门问问第七代 TTS 引擎,以单阶段、单流方式实现 TTS 生成,具备超自然的语音克隆与跨语种生成能力,可按需定制专属声音。
直击主流语音 token 痛点
- 解决语义 token 在生成声学特征时难以精准控制音色的问题。
- 简化多码本设计复杂度,增强语义关联性。
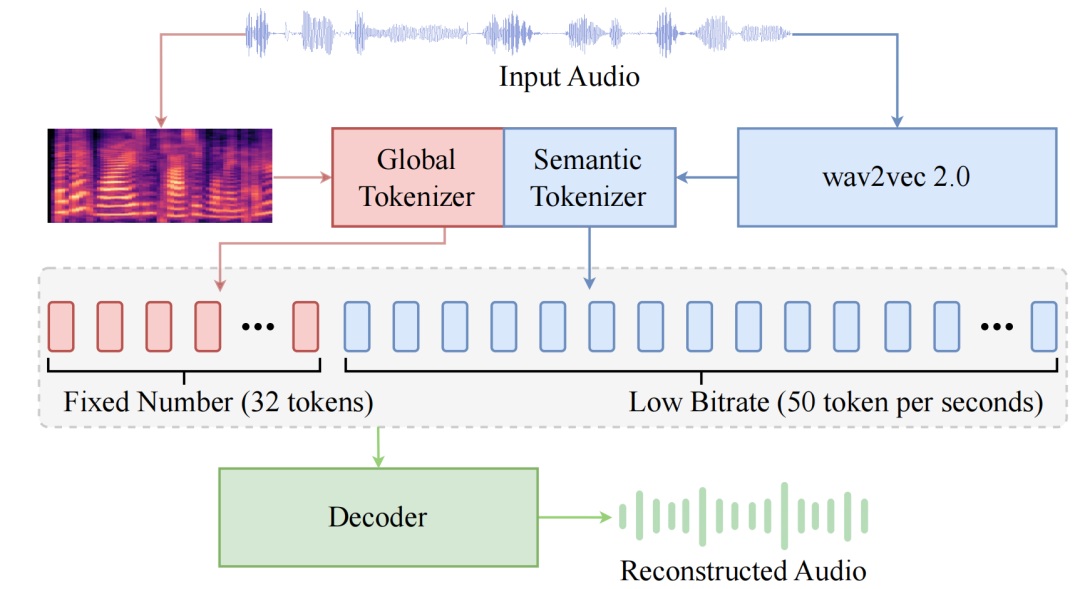
BiCodec 将输入语音编码为 Global Token 和 Semantic Tokens,确保语音生成全局可控性及语义强相关性。
实现建模结构与文本 LLMs 结构的高度统一
- 采用全离散、单流编码方式,使语音 token 建模与文本 token 建模完全一致。
- 通过属性标签和细粒度属性值,实现音色生成高度可控。
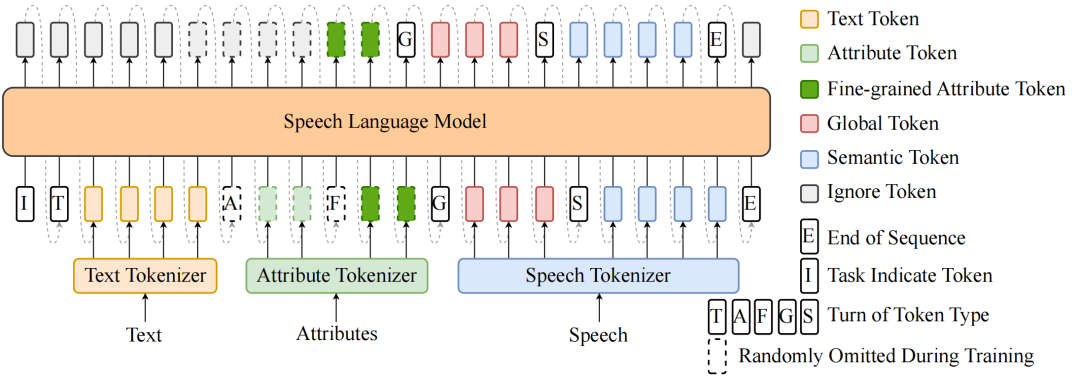
Spark-TTS 的语言模型示意图展示了其与文本建模的高度一致性。
TicVoice 7.0 技术优势
TicVoice 7.0 较上一代产品 MeetVoice Pro 全面提升,达到广播级水平。在 MOS 评分中表现优异,尤其在情感表现力和音色相似度方面表现突出。
3秒捕捉声纹: 实现超自然声线表达,精准合成日常闲聊自然音。
玩转特色声音: 精准复刻低语、呢喃等特殊音色。
情绪丰富多元: 模拟开心、生气、伤心等多种情绪。
多角色演绎: 为不同角色赋予鲜明独特的声音特征。
全龄段适配: 支持从孩童到老年各年龄段声音生成。
中英灵活切换: 提供跨境电商和语言教育领域的便利。
低设备门槛: 支持低质量输入音频的精准复刻。
TicVoice 7.0 的发布标志着出门问问在人工智能语音生成领域的重大突破,未来将持续深化与学术机构的合作,推动技术发展。




































