



 【建站扶持计划】
【建站扶持计划】 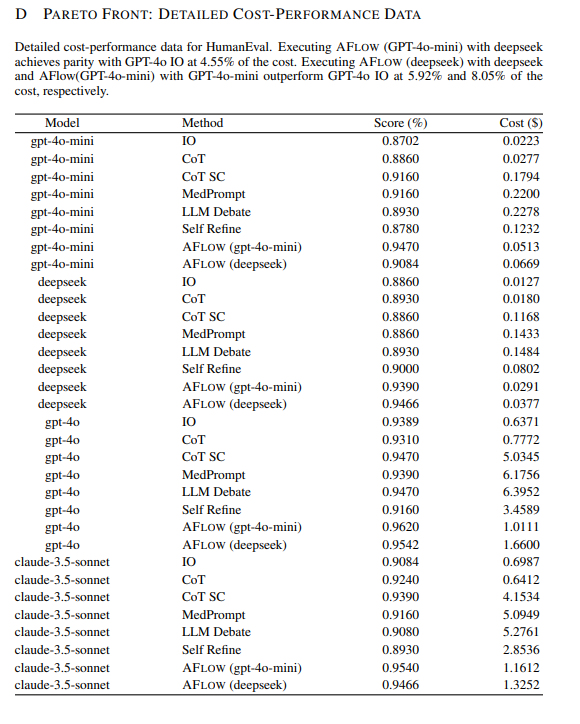
原文章地址:https://arxiv.org/pdf/2410.10762
说说文章的结论:
使用 deepseek 执行 AFLOW (GPT-4o-mini),在 4.55% 的成本下实现了与 GPT-4o IO(input和output) 相同的性能。
使用 deepseek 执行 AFLOW (deepseek) 以及使用 GPT-4o-mini 执行 AFLOW (GPT-4o-mini),分别在 5.92% 和 8.05% 的成本下超越了 GPT-4o IO 的性能。
结论实践结果:rag嵌入的方案,可以用更低的成本,达到更高模型的input和output 效果。
能力越强的模型,你需要的提示步骤越少。能力越差的模型,你挠破头训练他都没用,这是不是跟现实人事部门用人很相似?
结论:模型越好,提示词越简单,input消耗数量越低! 消耗数量低,但是input单价高,所以高级模型还是比低级模型价格高。
理论上3.5的 就算rag的平均input 是 4.0的 2-3倍以上。虽然 3.5 单价是4.0的 四分之一, 3.5 依然需要很多的input才能达到 4.0的效果。现在用3.5 没有性价比了 .
如果做了rag,你的input消耗大于2000 token,就说明rag的方式有误(90%的任务的input不会超过2000 token,一家之言,不喜评论区留言)
input 超过2000 token的问题分析和解决方案:
1.前置提示词过长(废话太多),解决办法-换高级的底层模型,比如gpt4o。
2.rag嵌入的知识库分类不够细,单个内容划分太粗糙,或者内容重复性太大!解决办法-人工做数据结构化,精简知识库结构。使用手动嵌入的方式。
3.匹配度不够高,可以设置语义匹配超过82%,增加内容匹配的精准度!
关于底层模型+rag在某些领域会超越高级模型的效果
用GPT3.5-16k微调成gpt4的效果,就好比你请一个高中生,通过自己的训练,可以把他训练成本科生的水平!但是你只需要支付一个高中生的工资,就可以拥有一个本科劳动力!
o1mini 通过微调可以超于o1的效果!是一样的道理。(算力的价格差距太大)

























