


![[动图] 李总为AI湿身,而5118老板连夜教你Python写AI自动玩游戏,快搬凳](https://cdn.10100.com/user/beb8a4f5863646f99562618332dec317.jpg?x-oss-process=style/180x)
昨天在百度AI开发者大会现场,正当李彦宏在现场讲解百度无人驾驶汽车自动泊车时,一名不明人士冲向演讲台并向他泼洒不名液体。李彦宏没有停止演讲,并在现场表示:“大家看到在AI前进的道路上,会有各种各样想不到的事情发生。但是我们前行的决心不会改变,坚信AI会改变每一个人的生活。”
虽然作为草根站长出身的我对百度也有几分异议,但是从李彦宏的现场的表现来看,确实必须为他点赞,只有在这种紧急的状态,才能看出一个的境界和修养,特别是那句“大家看到在AI前进的道路上,会有各种各样想不到的事情发生。”,甚至让我有点对他肃然起敬。
AI代替人类是个趋势是不可逆转的,在过去的几年里,随着真正大数据的来临,人工智能,特别是深度神经网络取得了过去人类数学家几百年难以逾越的一些鸿沟,这让大部分人都相信,在不久的将来,原本只能在《人工智能》这样电影里出现的小男孩,将真的出现在我们身边。
拥抱AI,这是未来职业生涯必须做出的选择,5118的好朋友们,应该看过上期的5118创始人李昊的公开课《》,虽然有些大神级的任务早就用上了这类技巧,但是抛砖引玉,通过这种思路确实能够解决工作中的很多自动化问题。
而今天要讲的神经网络不同,特别是以后可能要讲的无监督学习,已经可以做到无师自通,也就是说不需要人工干预,机器自己没日没夜的学习,就像周伯通的左右互搏,最终在各个领域打败所有人类。
Dota2世界冠军OG被OpenAI碾压
全程人类只推掉两座外塔
AI正在用无数的分身
试探出最佳的过关线路
AI学成后的贪食蛇
通过迁移学习
蒙娜丽莎居然复活了
通过GAN网络
杨幂自动替换朱茵
这就是近期最火的DeepFake
看到上面的演示,是不是有点小鸡冻,但是面对一个陌生的领域,我们该如何入门呢?
答案就是实践,用一个自己熟悉的简单游戏,再结合教程,对一次机器学习开发的整个过程进行一次完整的实操。
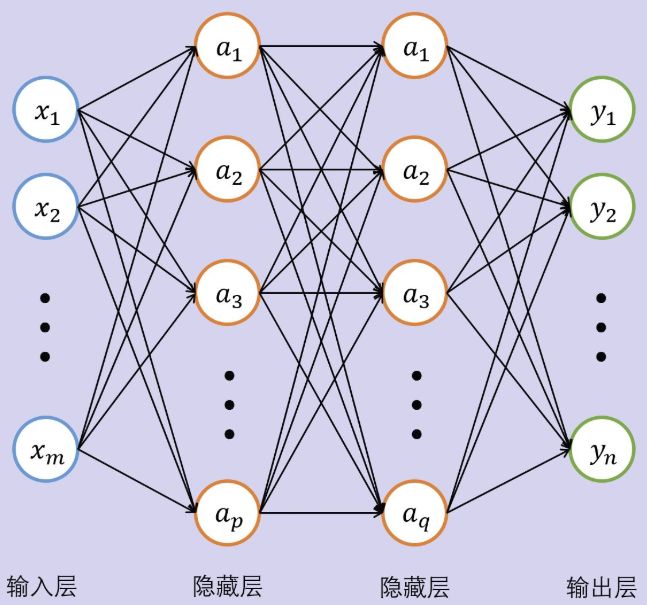
下面的课程,我将选择一个大家肯定都操作过一把的神游戏《扫雷》作为演练的对象,让我们看看一个多层感知机(简单的神经网络的一种)是如何学会扫雷的。
上图为多层感知机学习的场景,把每个小点想象成一个开关的话,上面表达的就是人类把扫雷棋盘传递给第一层,然后流经多层神经网络的多个层的每一个开关后,到达最后一层,然后根据最后一层和实际结果的误差,来反向调整个网络的参数,已达到后续能够预测任何没有学习过的扫雷棋局。
如果你还不知道扫雷的玩法,请参考这篇文章《》
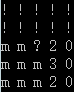
为了便于我们查看生成的数据,我们用几个字符来代替界面上的标识
m=迷雾,也就是还没有打开的位置
0=空地,代表这个周围都没有地雷
!=边界外,代表已经是棋盘外
?=中心待计算位置,也就是机器需要预测的位置
下面就是需要喂食给机器学习的数据样例
另外我们还要喂食问号这个位置的真实答案,也就是同时告诉机器问题和答案
[0,1] 或 [1,0]
如果第一个位置是1,代表没有有地雷
如果第二个位置是1,代表有地雷
同时告诉机器问题和答案10万次,这就是机器需要学习的经验,这就是有监督训练最基本的玩法
下面简单浏览一下代码,详细介绍都在注释当中
初始化环境
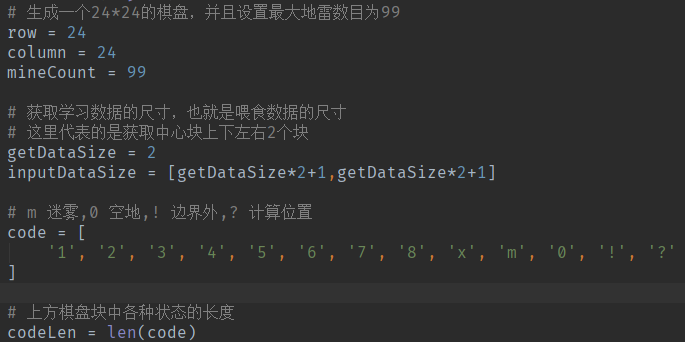
初始化棋盘,下面的代码都在initTable中

随机布雷
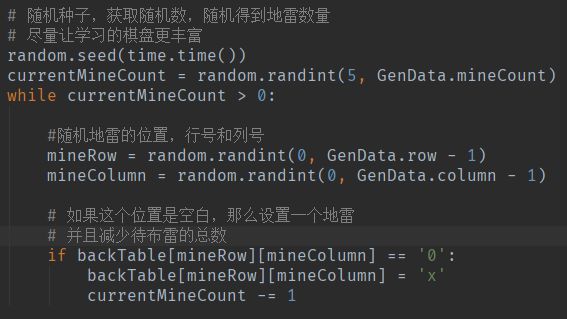
生成背后最终迷雾打开的全部棋盘
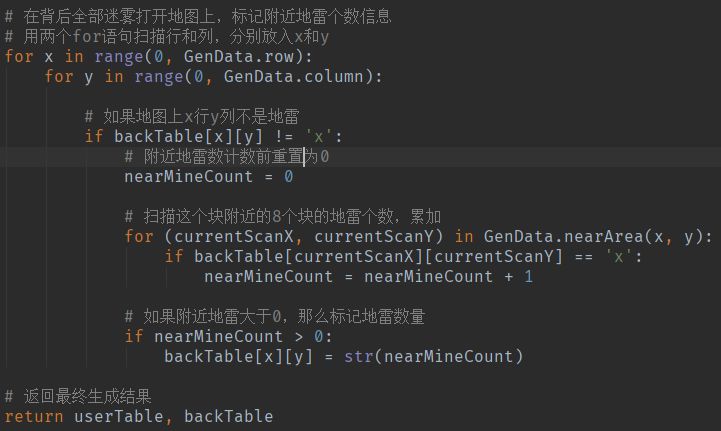
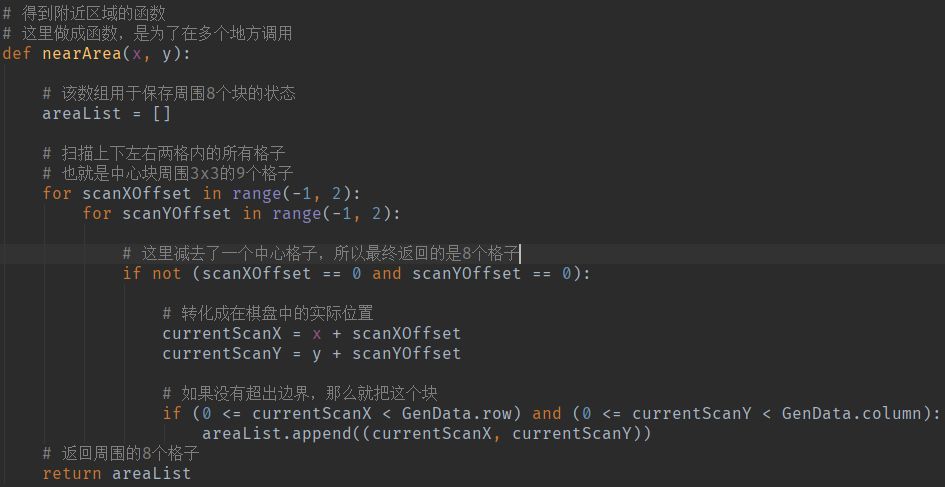
下面的代码是为了方便多处调用,获取周围8个格子坐标的函数,上面的布雷的代码中也用到了
返回的userTable中此时将会全是m,因为此时还没有任何点击

就像我们刚刚打开扫雷时,全部是未打开迷雾状态
backTable中将会是下面这样的

也就是全部迷雾打开的状态(下方图片不是上方数据的实际图片,仅作为演示)

有了上面的棋盘,我们就可以开始用下面的函数模拟人类来点击整个棋盘
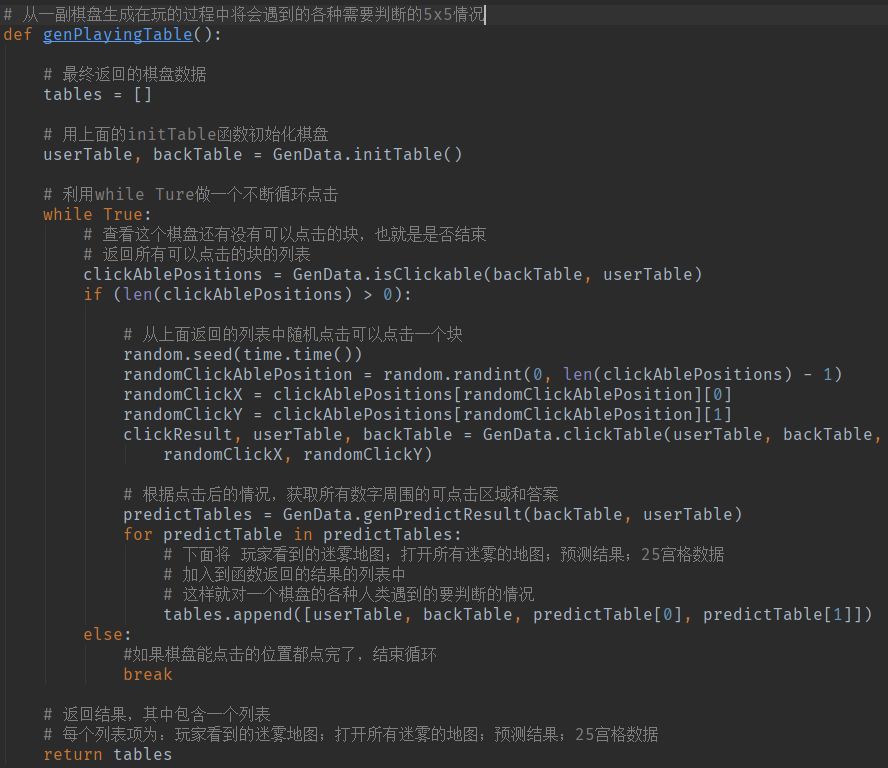
最终得到人类看到的各种棋盘场景和状态,其中人类需要判断的小的局面,把各种局面提取出来才能喂食机器,如:

上方为用户实际看到的图,我们从生成的期盼中提取大量类似上方的人类可能要遇到判断局面

下面是代码生成数据过程,得到大量5x5的扫雷过程可能会遇到的局面
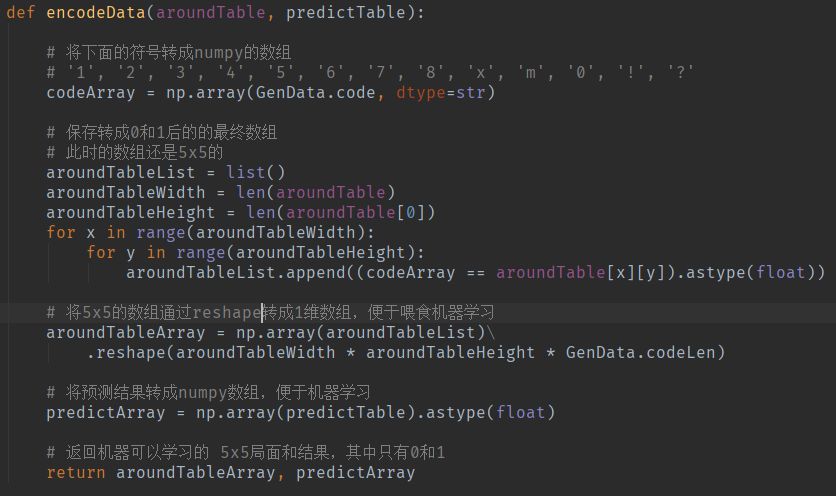
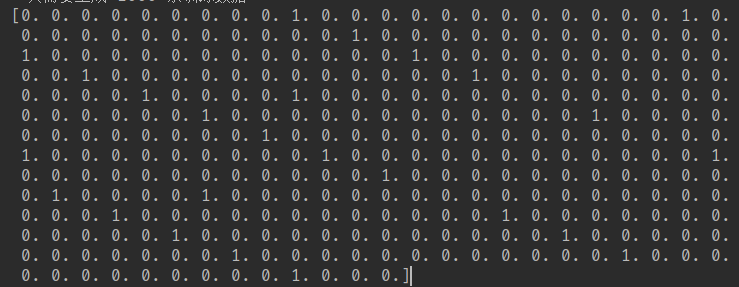
但是上面这些形式都是给人类看的,便于调试,其实机器学习的转化成0和1的数据,如:
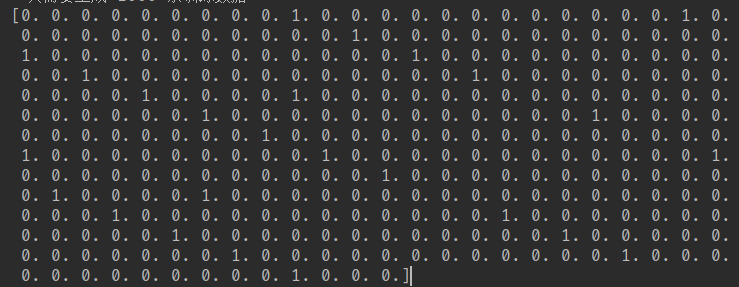
转化代码如下:
上面的代码已经把大部分如何生成喂食数据的部分讲完了,但是完整代码中还包括了一些如何快速生成棋盘的小技巧,如果需要完整代码,请到GitHub中查看:
通过把刚才生成的大量局面数据依次输入到x1到xm中,然后在最后一层y1到y2中得到我们想要的结果[0,1]或者[1,0],我们来构建神经网络
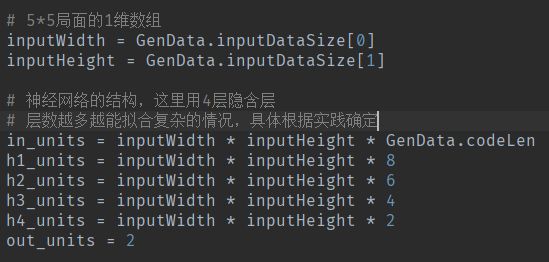
输入层节点个数有,5*5*编码列表长度,等于325个
1层隐含层有200个
2层隐含层有150个
3层隐含层有100个
1层隐含层有50个
输出层结果为0个,也就是[0,1]或者[1,0]
输入和输出结构:

第一层代码,注释中的一些代码是我在测试不同的一些设置时保留下的代码,里面涉及到了激活函数和抗过拟合的一些设置,以后的课程中会讲到
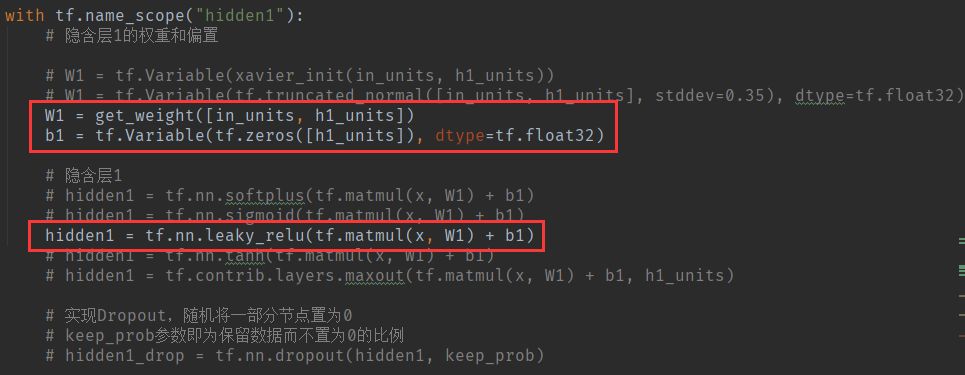
其他三层隐含层和第一层一样
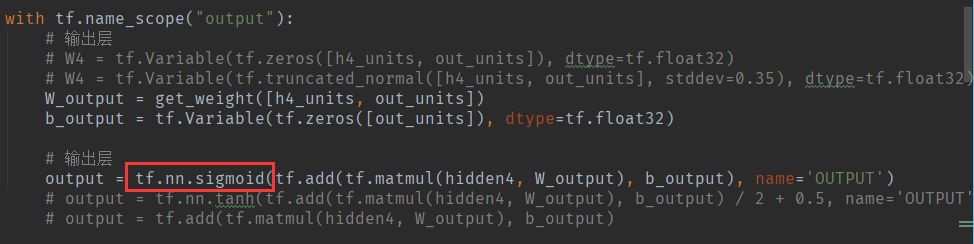
最后输出层,为了让输出在0和1之间,我这里用到了sigmoid这个激活函数,前面几层都是用的leaky_relu这个激活函数,神经网络每个节点都有激活函数
如果之前没有接触过神经网络,稍微理解一下就行,有点像一个开关根据所有的输入信号决定打开和关闭,就像人脑细胞有大量细胞对各种不同的信号有不同反应一样,一个大量节点的神经网络组合在一起,然后每个节点对不同的特征信号有不同的反应,这样就能够让整个网络足够拟合出复杂的函数。

最终我们把每一步训练得到的结果和真实结果差距的总和计算出来,让机器每一步根据这个误差来逆向调整整个网络的权重和偏置。
就像上图一样,机器一开始什么都不懂,然后一通乱算,算到了结果,和喂食的结果不一致,然后反过来用反向传播算法将误差传递回每个小节点,调整每个节点的参数,这里利用到了高等数学的链式求导,这里就不细讲,其实在tensorflow中都已经封装好了,只要使用,对于初学者来说,先不要细究,先上手才是入门的关键,如下:

我们使用AdamOptimizer这个优化器对整个网络进行调优,最终让整个网络计算出的误差在所有训练集中误差最小,整个过程如果可视化,就有点像怎么找到一个超平面的最小值,不同的优化器,有不同的策略,如下图:

我们通过上图代码喂食5x5局面数据和学习的预测答案[0,1]和[1,0]给网络学习,这些都是tensorflow已经封装好的一些工具,如果感兴趣我在后面的课程中将会详细介绍tensorflow的使用。
我们将生成的训练数据分成2部分,总共是5万数据:
一部分是给机器学习的数据,截取 9/10,下图蓝色部分
一部分是验证的数据,保留 1/10,用于测试机器在没学过的数据,正确率是多少,这部分叫做验证数据集,下图橙色部分
测试数据的误差和训练数据的误差能够同步降低,这种是最好的情况,说明机器学习将知识泛化到了没有学习过的位置
而如果训练数据的误差不断减低,而测试数据的误差不断增高,那说明训练导致了过拟合,这里我们要通过一些正则化策略来防止,例如L2正则或者Dropout丢弃训练节点策略,这些可以以后学习tensorflow的时候再补课,本例中我们用到了L2正则来防治过拟合。
最终我们训练的误差结果如下图,蓝色代表训练数据集的误差,橙色代表测试数据集的误差,我们看到训练一开始迅速下降过后,就保持在一个固定值,说明这个时候机器已经学习不到新的东西了,早就可以停止
下面是准确率的数据,代表预测大概会有87%的准确率
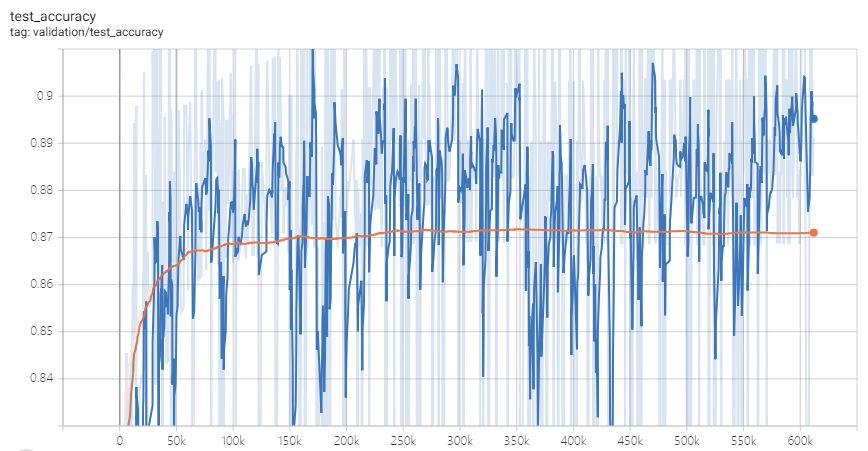
之后我又再生成了5万训练数据,但是发现准确率不再明显提高,说明目前已经无法通过增加训练样本来增加准确率了,所以训练可以停止
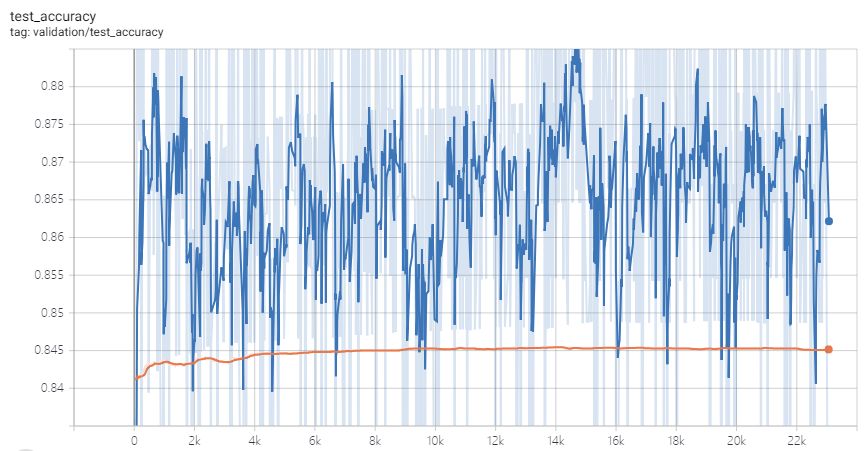
训练代码大家请到GitHub中查看:
测试代码请查看
为什么不能到100%的准确率?因为我们喂食的数据里面含有一些模糊的局面,例如一个局面可能是多种的可能性
例如上图,我们人类也不清楚到底这个位置是不是地雷,但是在我们的训练数据中包括了这种模糊的数据,所以神经网络最多只能训练到87%
解决办法是我们把这个网络生成的判断结果再放入到另一个网络中训练,一旦遇到没有把握的情况,机器就跳过,优先做自己最有把握的局面,第2个网络教第一个网络不要逞强。
第二个网络我就不详细展开讲了,和上面提到的方法是一模一样,只是喂给机器的数据是5x5局面和第一个网络是否能够预测成功的结果,我们通过第一个网络生成一批给第二个网络训练的数据就行了。
通俗说,就是用第二个网络打探一下,第一个网络能不能算准?如果能,那么就用第一个网络标记出是不是地雷。
码完字,现在已经是早上7点,当我回过头来看,发现本文涉及的东西确实太多:
1、基础python编程
2、神经网络(Tensorflow编程)
3、如何截图并模拟点击(windows编程)
4、识别格子上的标识(卷积神经网络)
只因受到宏颜获水事件刺激,连夜7个小时写出这个教程,希望大家大致能够了解AI是怎么工作的,其实完成一个AI玩游戏的过程并不容易,想要在一篇文章里面能够讲解清楚,教会大家确实有点操之过急,如果5118的好朋友们希望我能够继续传授大家这类知识,请一定在下面留言让我知道,因为我也在权衡是否还需要坚持为5118粉丝提供Python+Seo+人工智能的实战课程,有您的鼓励才会得以坚持。
用CNN卷积神经网络和LSTM做验证码识别

用Python如何建立自己的海量代理IP库
用Python自动登录和发帖
用TensorFlow自动去水印

用Python控制手机中的微信自动开红包
用Python控制手机APP,如:抖音
用Python+Tensorflow玩更多的游戏
用Python+Tensoflow做DeepFake



























