




这几天挺热闹的, Google AlphaProof和AlphaGeometry 2在IMO2024上拿了银牌28分, 对于System2的研究是我一直在做的一块东西, 特别是DeepMind 好几个科学家在做的一些工作都是非常有意义的.另一边OAI SearchGPT也出来了. 挺有趣的一件事情是, Google都开始卖现货了, OAI无论是Sora还是SearchGPT都成了卖个情怀的期货, 然后GPT5又不停的延期...
国内大模型来看, DeepSeek在五月也有一篇DeepSeek-Prove的论文也有布局, 并且最近API增加了Function call的能力, 然后最近也在开始扩招了,看样子MLA带来的推理盈利让它走上了快速发展的道路.
当然这周最重要的是Llama 3.1 405B的发布, 随之公布的技术报告诚意满满. 我们将分几篇文章来分析Llama 3的技术报告, 第一篇从大家关系的基础设施和并行策略谈谈, 后面再继续谈谈数据清洗, 训练过程, 对齐, 多模态等一系列内容.
对于基础设施中,最大的变化是,Meta放弃了原有的非对称拓扑的多轨道部署,转而采用对称拓扑结构,并在Spine交换机中引入了Broadcom的Jericho-3 AI DDC技术来规避大规模组网的Hash冲突相关的问题. 对称拓扑对于任务编排和故障爆炸域的控制以及宕机快速迁移都有巨大的优势, 但是整个网络成本也会高接近30%以上.
吐个槽,多路径算法和拥塞控制它还是搞不定...Incast没搞定,这就导致所谓的MoE搞起来很复杂, 最终上了大Dense(当然从算法上Dense还是有优势的, 下一篇会详细从Presheaf的角度讲), 所谓的Enhanced-ECMP也是在改交换机的Hash函数, 是男人就不考虑交换机的任何Hash函数, 不管交换机任何ECN, 不需要Deep Buffer交换机, 从网卡上把所有事情解决干净
另外还有一个值得关注的,Meta构建了两套 24K H100的集群. 一套基于RoCE,一套基于IB. 最后得出的结论是经过优化后,两套性能一致. 那么英伟达吹的神乎其神的SHARP,Microbenchmark看上去性能贼好, 实际业务收益毛都没有. 那么还搞什么在网计算呢? 在网计算要搞, 但是要有一个很好的体位.
1. 计算
采用8卡的H100-80GB SXM服务器, 物理服务器采用OCP Grand Teton[1]平台, 这个平台计算网络和GPU机尾的插槽式设计使得维护的时间可以大大的缩短, 但看到故障统计时也出现了两次服务器机框相关的损坏, 脑补了一下, 例如拔插GPU槽时导致背板接插针撞歪等故障?

单个集群24K卡. Llama-3 405B最大训练规模为16K卡. 集群管理和调度是OSDI‘24 刚发布的一篇论文《MAST: Global Scheduling of ML Training across Geo-Distributed Datacenters at Hyperscale》[2] 后续我们将单独进行一个详细的解读.
2. 存储
存储采用了自研的分布式文件系统Tectonic[3], 7500台服务器提供240PB的存储能力, 支持平均2TB/s峰值7TB/s的写入能力. 存储集群在油管上有一个介绍视频《Training LlaMa - A Storage Perspective》[4]和通用计算集群相比, 它有如下特征

对于Burst的读写及I/O完成的延迟更加敏感, 同时在成本上相对并不是那么的敏感. Checkpoint的写入为每个GPU 1MB~4GB的文件大小.
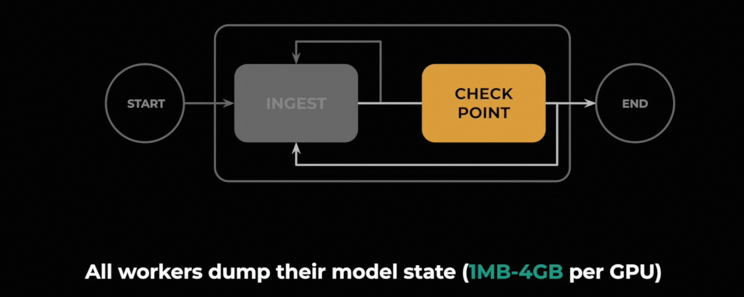
对于存储的需求, 考虑到GPU的故障和服务器故障的快速恢复, 本地SSD盘的存储并不合适,更多的需要Checkpoint到外部存储, 因为checkpoint带来的大量的Burst, 很高的IOPS和带宽需求, 因此需要一个单独的集群
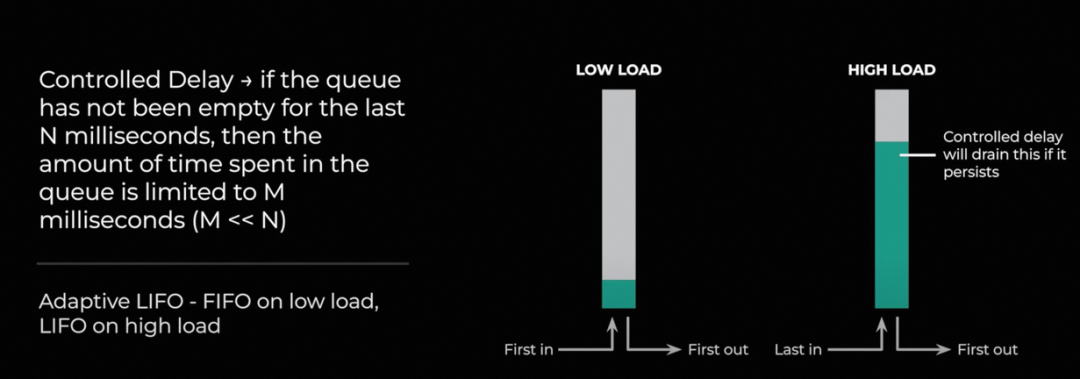
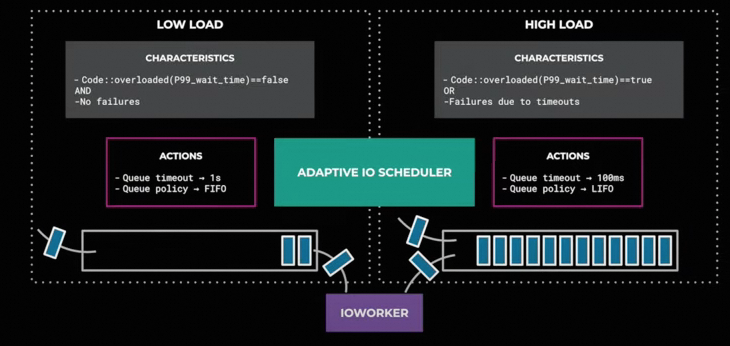
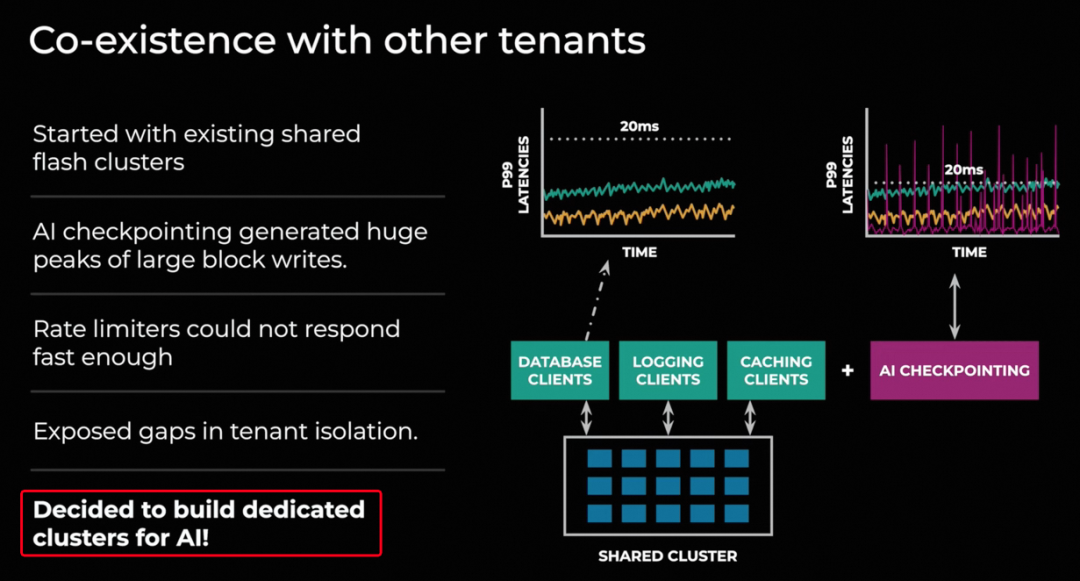 在写入IO时, 由于过高的吞吐导致延迟增加,并且伴随着一些写入失败
在写入IO时, 由于过高的吞吐导致延迟增加,并且伴随着一些写入失败
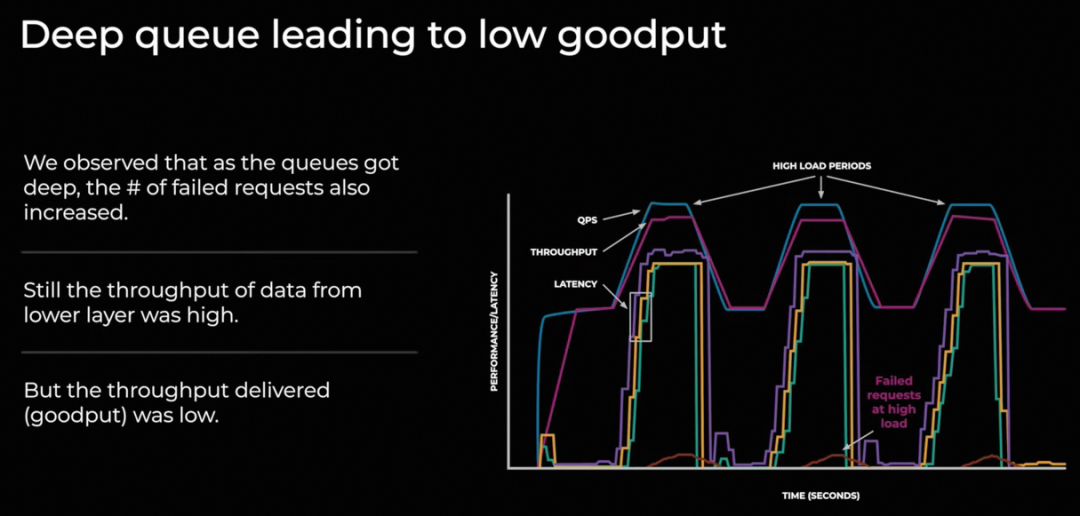
对于一些Stale的IO请求需要拒绝来避免对吞吐的影响
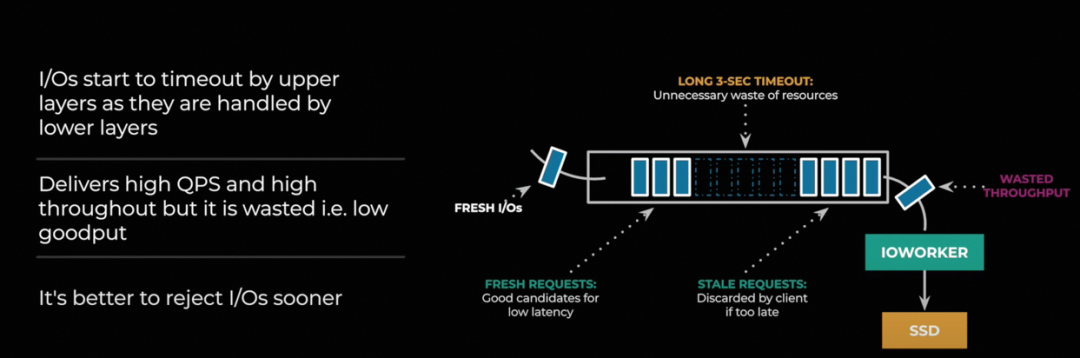
因此在较高的IO Load下采用了LIFO队列
3. 网络
早一些的集群建设, Meta都在采用多轨道的部署方式《Optimized Network Architectures for Large Language Model Training with Billions of Parameters》[5], 如下图所示
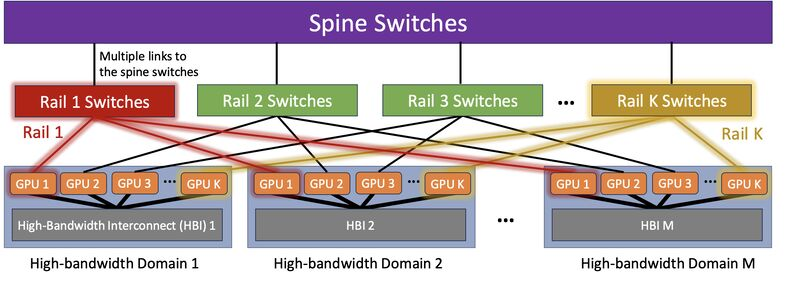
通过相同Rank的GPU接到同一个Rail的交换机上, 基本上国内的几个公司的拓扑也是采用这种方式. 通过这样的方式可以避免一些Hash冲突带来的影响, 尽量将流量调度到Rail交换机上. 然后对于上到Spine交换机的流量,通过一定的编排和指定NCCL通信库选择源UDP端口的方式来错开,无论是Meta还是国内的阿里/百度/腾讯/字节都基本上采用这样的方式.
这样的拓扑可以构建千卡规模的完全无冲突的互联, 但是这样的拓扑也会带来一系列的问题. 一方面是任何一个卡有了故障, 必须要在同一个Rail交换机下找到一台备用机器. 而任何一台Rail交换机故障都会导致整个千卡集群规模的受损.并且为了满足布线的需求, GPU网卡到Rail交换机之间只能使用AOC光缆, 这样不但增加了成本,同时还增加了故障率. 非对等的拓扑结构也给并行策略编排和调度带来了极大的挑战.
我一直是反对通过拓扑的方式去解决Hash冲突的问题, 一定要用更加对等的拓扑来做, 并且通过网卡的算法去解决Hash冲突问题, 并且做到对交换机Hash函数不感知. 很高兴看到Meta在新的H100集群做出了改变, 回到了原有的Spine-Leaf的架构.
3.1 网络拓扑
每个机柜放置两台H100服务器, 每个服务器8个400Gbps单口的网卡, 然后两台服务器连接到同一个TOR Switch上. 它并没有使用2x200G得冗余保护机制, 因此在故障中断中网络的占比较高.
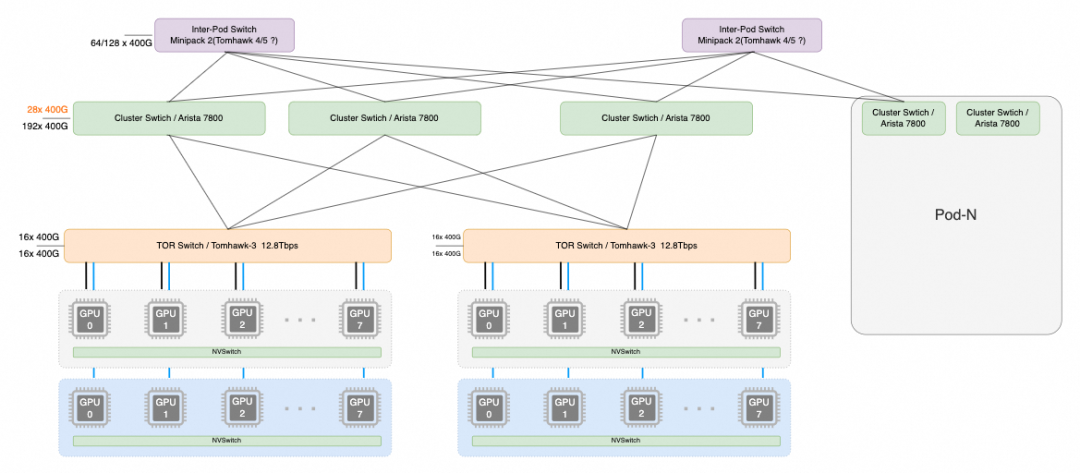
整个拓扑如上图所示, 一个机柜两台服务器16卡H100, ToR交换机为基于TH3 12.8T或者Cisco Silicon One 12.8T的交换机.下行16个400G端口, 上行16个400G端口连接Cluster交换机, 每个Pod有192个机柜,按照1:1无收敛的方式连接到Cluster交换机.
Cluster交换机采用了Arista 7800的框式交换机架构, 线卡采用BRCM Jericho-3系列芯片, 片上Buffer更大,同时携带了HBM作为Off-chip buffer, 更容易吸收集合通信带来的突发流量, 如下图所示

在一个Pod内有16 * 192 = 3072个H100, 它们之间互联的通信距离为最大经过3跳交换机. 选择框式交换机还有一个好处是,它可以单个交换机提供更大规模Radix互联, 例如Meta的拓扑需要192+28个400G接口在单台交换机上. 总吞吐需求要86Tbps, 已经超过了最大的单颗交换机芯片51.2Tbps极限. 而基于Jericho 3+ Ramon的可以将单个交换机的密度通过多级交换+VOQ的方式进一步扩展到576个400G端口.
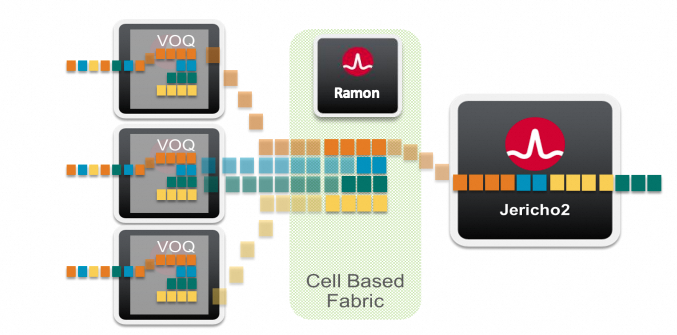 即Jericho3将数据切分成信元, 然后均匀的分担到多颗Ramon Fabric卡上, 最后再汇聚到出方向的Jericho线卡上. 中间采用了Virtual Output Queue的调度算法.
即Jericho3将数据切分成信元, 然后均匀的分担到多颗Ramon Fabric卡上, 最后再汇聚到出方向的Jericho线卡上. 中间采用了Virtual Output Queue的调度算法.
 依照当前Meta的部署, 选择288 x 400G 端口的平台即可, 这样还有一些可运维的好处. 端口实际上只使用了220个, 还有64个剩余. 这样对于Cluster交换端口坏或者线卡坏都可以很快的进行维修替换, 甚至是Fabric转发引擎故障也可以快速替换.
依照当前Meta的部署, 选择288 x 400G 端口的平台即可, 这样还有一些可运维的好处. 端口实际上只使用了220个, 还有64个剩余. 这样对于Cluster交换端口坏或者线卡坏都可以很快的进行维修替换, 甚至是Fabric转发引擎故障也可以快速替换.
然后另一方面多路径Hash冲突的问题, 由于Cluster交换机内部可以做信元切分和VOQ转发, 并且Jericho的深buffer特性也可以很好的吸收集合通信带来的burst. 因此只需要在TOR交换机上考虑解决Hash冲突即可.
当然这样的方式也带来一个问题, 整体网络建设的成本会上升30%以上. 另一方面GPU上联仅有1个400G端口, 增加了故障中断的概率,但也避免了两个口带来的Hash冲突.
最后24K卡由 8个3072卡的Pod互联构成, 但是Pod之间的带宽有1:7的收敛比. 这会拖慢集合通信的性能, 但是Meta将DP并行通过FSDP overlap后, 隐藏了延迟, 因此在这里构建一些带收敛比的网络也未尝不可. Inter-Pod的交换机采用Minipack 2, 基于BRCM Tomhawk 4 或者Tomhawk 5构建.

渣的评价:
好的方面:
-
恢复到标准的Spine-Leaf对称拓扑, 接入TOR交换机到网卡这一段就不需要采用光模块了, 省了不少成本, 单个400G光模块大概$1000美金. 同时铜缆也提高了稳定性. -
爆炸域缩小, 如果某个GPU故障, 或者TOR交换机故障, 仅需要很快的迁移到另一个机柜上就行了, 爆炸域16卡, 单个Pod有3072卡, 而Llama 3 405B训练规模为16384卡, 从并行策略看正好每个Pod 2048卡, 因此每个Pod其实可以分为2048+ 1024, 剩下的1024卡还可以跑一些别的业务, 当故障发生时, 很快的杀掉小的任务来替换保证2048卡的训练即可. -
而多轨道的部署, 如果TOR故障或者某个GPU服务器故障将会影响到千卡规模. -
多轨道的非对等连接, 有些大厂采用在TOR上做DP, 更上层交换机做PP的方式. 在CP并行引入后,事实上这样的拓扑会带来更多的问题. 同时MoE的Bisection带宽也无法保证. -
Spine采用了框式交换机, 更深的buffer可以吸收集合通信的burst, 同时基于VOQ的Linecard+Fabric方式扩大了交换机的Radix, 可以支持最大576个400G端口互联. 而交换机模块化的设计, 留了64个口用于端口故障时的更换, Fabric也有冗余. -
Spine整个交换机故障,整个集群的通信量仅下降1/16. -
集合通信可以在有收敛比的网络中很好的运行(在集合通信那节详细展开).
待完善的:
-
多路径的问题转移到了框式交换机上, 网络成本上升了30% -
我们还是需要更仔细的从根源上去解决RoCE的多路径的问题, 但是Meta当前是没有解决的. -
alltoall的通信问题实际上是没有解决的, Meta一直在Call for action. 当然Meta也没有使用MoE模型, 序列并行等也没有采用alltoall的通信算子, 但这对Meta未来模型演进到1000B十万卡规模还是有挑战的. -
单口400G,单上连带来的可靠性问题, Meta需要考虑双上联提高稳定性的情况下, 增加两个Hash冲突点如何避免冲突
3.2 负载均衡
由于Cluster Switch采用框式可以实现高Radix的非阻塞通信. 因此负载均衡的问题只转移到了接入的TOR交换机上. Meta做了两方面的工作, 一方面是在通信库上, 通过NCCL_IB_QPS_PER_CONNECTION=16来将流量打散到多个QP, 但是这样会导致集合通信的性能有所下降.
另一方面他们又造了一个新名词Enhanced-ECMP协议, 实际上就是把RoCE头中的Dest QP加入到交换机的Hash算法中. 在Tomhawk交换芯片上大概就是几行配置的问题, 这也能叫协议?
3.3 拥塞控制
主要是通过Cluster Switch上的Jericho Deep-buffer来吸收集合通信带来的Burst, 这样也不需要搞DCQCN了, 我一直说ECN和PFC这两玩意做CC配合在一起就是翔总有人不信, 美国人也这么搞了,软骨症好些了没? 膝盖还疼么?
是男人就不考虑交换机的任何Hash函数, 不管交换机任何ECN, 不需要Deep Buffer交换机, 从网卡上把所有事情解决干净
4.并行策略
Llama 3 405B最开始采用8K的SeqLength 3D并行训练了15.6T Tokens. 然后再加入CP并行,将Context Length按照6个Stage增加到128K, 可能的做法是(8K, 16K, 32K, 48K, 64K, 96K, 128K)逐渐增长, 大概这个Long Context Pre-training过程用了800B tokens, 在并行策略上标准的8K训练采用了8K卡和16K训练, 大概的猜测是前期采用8K集群在训练405B,等70B结束训练后再将其它8K张卡加入构建了16K的并行任务, 为了保证BatchSize一致, 对DP并行和Micro batchsize进行了调整. 并且保证三种并行方式下的每个Batch下的Token数量时一致的.

并行时的编排维度如下图所示:

按照[TP,CP,PP,DP]的顺序编排, 所有的并行策略TP=8即TP的流量在单机8卡内NVLink上承载.
-
标准的8K SeqLength训练:CP=1,PP=16,PP并行的流量会在Cluster Switch上. 然后DP=64/128, Meta应该可以通过MAST进行一些亲和性调度和Hierarchy Reduce等做法尽量将流量在ClusterSwitch上处理, 少部分流量跨越Pod到Inter-Pod Switch
-
Long Conext训练:CP=16,PP=16,此时依然可以保证CP和PP的流量在ClusterSwitch上终结, 而DP流量穿越Inter—Pod交换机.
整个训练的MFU大概也维持在了38~43%, 需要注意的是Meta在整个训练过程中不光考虑MFU还考虑了内存的利用率.
4.1 DP并行
DP并行采用了FSDP进行Overlap,同时这些相对异步的通信延迟影响和带宽影响并没有那么显著, 因此Meta将其在网络的最外层, 并穿越了带1:7收敛比的Inter-Pod交换机. 而国内还有一些把DP放在最内层的做法相对来说是不妥的.
4.2 PP并行
Llama 3 405B在PP并行时, 模型结构上从128层降低到了126层, 分为16个Stage, 第一个Stage和最后一个Stage仅有7层, 中间的每个Stage有8层. 这样做的一个好处是, 第一个Stage通常需要更多的内存处理Embedding和micro-batches warmup. 而在最后一个Stage需要计算Output和Loss 这一级的计算量不均衡导致延迟更大, 因此Meta采用首尾各少一层的方式来平衡每个Stage的计算量和内存用量.
另一个问题是BatchSize约束, 记 为单个Stage连续的Micro-batch数量(MBS), 记 为Micro-Batch的总量. 当采用DFS调度策略,要求N和PP Stage数量相同, 而采用BFS调度要求N=M. 作者修改了PP的调度方式, 如下图所示:

N可以在[0,M]的范围内任意设置. 这样每个Batch中都可以执行任意的MicroBatch. 这样可以:
-
当BatchSize受限时,采用比Stage更少的MBS. -
更大的MBS来隐藏Pipeline延迟
另一方面为了减少流水线空泡(Pipeline bubble), 作者采用了1F1B Interleave调度的方式. 同时通过TORCH_NCCL_AVOID_RECORD_STREAMS降低异步P2P通信的缓存用量. 然后为了进一步降低内存开销还进行了Profiling, 主动释放后续不会使用的Tensor, 例如每个PP Stage的input和output Tensor. 然后可以在8K训练长度小保证内存充足不需要使用Activation checkpoint,降低了重算的代价.
4.3 CP并行
CP并行作者引用了Ring Attention[6]的论文, 通常会采用通信和计算Overlap的方式.
但是作者使用的CP实现和论文有不同. 因此采用首先All-Gather拿到KV Tensor, 然后再本地基于Q Chunk进行计算. 这样的好处是可以灵活的支持不同的Attention Mask机制. 但是也带来了一个坏处,All-Gather操作的通信延迟无法被隐藏. 考虑到模型时GQA的, KV tensor远小于 Q TEnsor的数量, 因此Attention的计算时间远大于All-Gather, 因此Allgather的通信开销就可以忽略了.
注: 在国内腾讯的方佳瑞博士还提出了一种USP的并行策略, 可以供参考《USP: A Unified Sequence Parallelism Approach for Long Context Generative AI》[7]
5. 通信库
主要的通信原语是All-gather,Reduce-Scatter和P2P Send/Recv, 其中PP和DP并行由于要跨越多个交换机,延迟达到数十个微秒, NV开源的NCCL也有一些问题, 例如需要交换大量的小通信量的控制消息, 额外的内存拷贝, 需要更多的GPU Cycles进行通信.
Meta基于NCCL进行了修改了一个NCCLX的库, 一方面是Tuning通信size, 另一方面是针对控制消息在交换机中配置了低延迟高优先级队列.并且还在持续深入的修改通信库. 另一方面是通信库修改来提升可靠性,在故障时尽量快的检测出来问题. 例如对通信Kernel相关的网络活动, RingBuffer等状态进行记录分析, 以及NVLink上的LD/ST挂起的操作等进行快速的检测, 并触发主动性运维.
6. 稳定性和运维
在整个54天的训练中, 遇到了466次任务中断, 其中包括47次主动中断用于调整数据集升级Firmware等. 但是有419次非预期中断, 平均3小时中断一次. 78%是硬件问题. 由于自动化运维, 只有3次非预期中断需要人工干预, 因此整个训练过程中的有效训练时间高于90%. 故障事件列表如下:
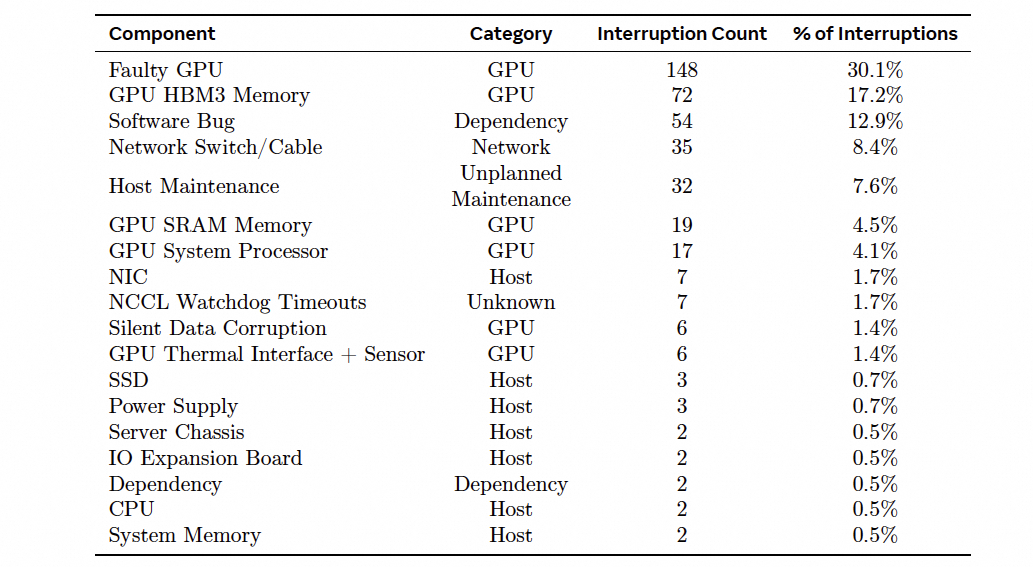 对于GPU的故障, 由于新的Spine-Leaf架构, 可以很容的进行宕机迁移, 爆炸域仅2台机器. 因此大量的硬件错误可以不需要人为干预很快就切换掉. 同样软件故障也可以很快的重新拉起.
对于GPU的故障, 由于新的Spine-Leaf架构, 可以很容的进行宕机迁移, 爆炸域仅2台机器. 因此大量的硬件错误可以不需要人为干预很快就切换掉. 同样软件故障也可以很快的重新拉起.
其中还有35次网络交换机和线缆的故障, TOR故障可以很快的迁移, 爆炸域为2台. 对于ClusterSwitch只是短暂的集合通信性能下降1/16, E2E的吞吐性能下降影响较小, 而且框式交换机有冗余的端口可以很快的切换线缆, 即便是LineCard故障也可以很快迁移, 而Fabric Card也是有多块,可以很快的进行更换.
另一个有趣的事情是, 每天中午系统的吞吐会下降1~2%主要是因为GPU温度过高导致的降频. Grand Teton的散热是否还有一定的问题呢? 另外在训练过程中由于所有的服务器同时启停, 对于供电的干扰很大, 对于未来10万卡集群是需要考虑的一个问题.
7. 小结
从Rail-Based多轨道拓扑回归到Spine-Leaf的拓扑是正路, 因为我一直就反对Rail-Based拓扑.
一方面是对等的拓扑对于编程和并行策略开发更加友好, 特别是针对万卡,十万卡规模时的4D并行.另一方面是可靠性相关的问题, Rail-Based故障的爆炸域达到千卡规模, 对于GPU服务器故障通常需要在同一个爆炸域内放置备用机.
当然这样的拓扑由于RDMA没有解决多路径的问题和拥塞控制问题, 因此需要采购框式Deep Buffer交换机, 采用Linecard+ Fabric 并使用VOQ机制来解决, 网络成本提高了30%. 当然还有更大规模下和国内算力不足采用MoE模型, 以及一些SP并行带来AlltoAll incast的问题都是非常困难的.
Meta的这篇报告还是非常诚意满满的, 我们还看到在模型上针对PP并行进行了调整, 针对长Seq采用了渐进的增加Seq训练方式,大量的训练Tokens(15.6T)避免了CP并行, 仅使用了800B Token逐渐从8K扩展到128K SeqLength. 同时利用GQA的特点针对长文本CP并行采用了Allgather, 也避免了Alltoalll的使用, PP调度也很好的隐藏的延迟.而针对DP并行本身就可以很好的Overlap时, 并没有追求极致的DP集合通信优化,而是采用了1:7收敛比的网络, 降低了网络成本.
还有一个亮点是通过这个RoCE集群,证明了老黄吹的IB和SHARP特性的性能基本上也就是Microbench mark的收益, 而没有实际的E2E收益,两个24K卡集群性能几乎一致.
这些针对可靠性/宕机迁移/降低爆炸域的设计, 针对用户可编排性的对称拓扑设计都是值得我们学习的, 当然也有一个槽点, Meta还是没有办法去解决RoCE多路径/乱序/Incast拥塞控制的问题,被迫多花了30%的钱买框式交换机.
所以还是继续提出一个已经解决的问题:
采用Spine-Leaf拓扑, 不用任何框式交换机, 如何不利用交换机任何Hash函数信息, 不需要交换机任何特殊配置, 不启用ECN和PFC. 通过网卡算法自动打散流量,并维持交换网97.5%以上的利用率, 对于交换机的buffer需求为队列深度低于3us. 并能够针对128:1的时候incast时最大流和最小流量之间的带宽差异小于100Kbps, 同时针对任何网络线缆故障, 通信中断无感知, 模型训练收敛时间小于100ms.
全球能做到的就一个算法, 至于那些叫得上名字的国际大厂们, 要么在交换机Hash函数上瞎折腾, 要么就在扯per flow PFC...
大概这篇关于Llama 3 AI Infra的解析到此为止吧.
grand-teton: https://engineering.fb.com/2022/10/18/open-source/ocp-summit-2022-grand-teton/
[2]MAST: Global Scheduling of ML Training across Geo-Distributed Datacenters at Hyperscale: https://www.usenix.org/system/files/osdi24-choudhury.pdf
[3]Tectonic: https://www.usenix.org/conference/fast21/presentation/pan
[4]Training LlaMa - A Storage Perspective: https://www.youtube.com/watch?v=S9c27b-jD0c
[5]Optimized Network Architectures for Large Language Model Training with Billions of Parameters: https://arxiv.org/pdf/2307.12169v2
[6]Ring Attention: https://arxiv.org/abs/2310.01889
[7]USP: A Unified Sequence Parallelism Approach for Long Context Generative AI: https://arxiv.org/pdf/2405.07719


