Screaming Frog(中文名“尖叫青蛙”,以下简称“青蛙”),是一个我们在日常工作中使用得非常频繁的工具,如果让我用一句话来概括“青蛙”的功能,我觉得:
“它是一个通过模拟搜索引擎爬虫,来抓取并分析网站中各式各样的信息和内容的工具。”
相比于人工检查网站,“青蛙”的核心优势在于:
效率高:它可以快速抓取大量页面,并自动分析数据,而人工检查网站则需要耗费大量时间和精力;
全面性:它可以检测到人工检查容易遗漏的网站问题,例如内链问题、代码错误等;
客观性:它的分析结果是基于数据的,因此更加客观、公正;
可持续性:它可以定期自动检测网站问题,帮助网站运营人员持续监控网站健康状况。
由于“青蛙”抓取的对象是“网站”,而“网站”是包括“自己网站”和“其它网站”的,所以我们在使用“青蛙”时,不仅可以用来自检,也能用于竞品分析。
因此,这篇文章会从“自检”和“竞品分析”两个维度,来跟大家分享一下,我们是如何使用“青蛙”来解决网站SEO问题和提升效率的。
使用“青蛙”来自检
【需求背景】
内链,是将用户和搜索引擎爬虫引导至网站上其它页面的重要桥梁,因此对于网站的SEO非常重要。
而404错误内链,会导致这个桥梁的中断,因此我们必须定期去修复网站中的错误内链。
然而,通过人工去一个页面一个页面的找,肯定是不太现实的,耗时耗力,效率太低。
【解决办法】通过查找被抓取页面中,返回状态码为404的页面,筛选出哪些页面存在404错误内链,并快速定位这些错误内链所处页面中的位置。
排查网站中使用JS生成的重要内容
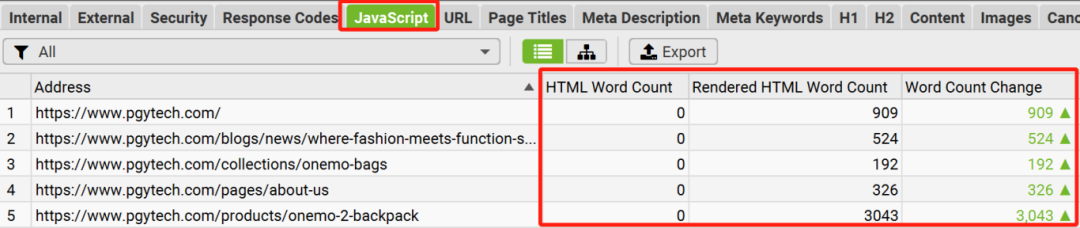
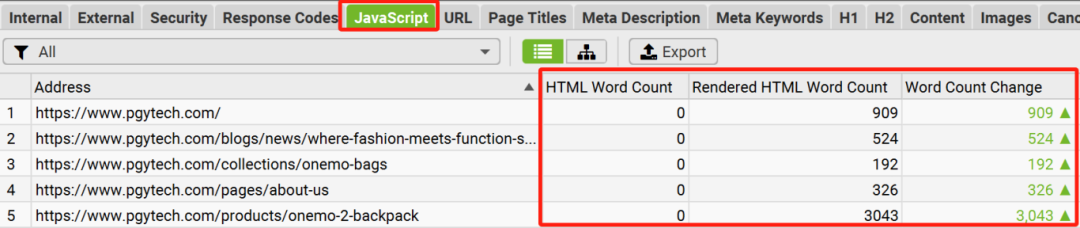
【需求背景】
Javascript 可以让用户跟网站的交互非常丰富,提升用户体验。因此,对于如今的网站而言,Javascript 的应用非常普遍。
但是,对于搜索引擎爬虫而言,重要的内容(例如内链,文字),如果是通过Javascript来动态生成的话,会使得搜索引擎对页面的快速加载及完整渲染产生问题,从而导致页面排名不佳的后果。
【解决办法】通过在“青蛙”的设置中,启用Javascript渲染功能,来对比启用该功能前后的文字内容结果差异,来快速判断自己的网站是否有严重的Javascript渲染问题,从而确定网站Javascript SEO优化的优先级。
定期自动生成XML Sitemap
【需求背景】
如果你的网站是自建站,而不是使用常见的CMS平台(例如Wordpress或Shopify)的话,就很有可能要定期手动生成Sitemap文件。
市面上的确有很多的XML Sitemap生成工具,但是要做到自动、定期且免费生成的话,可能是没有的。
【解决办法】通过使用“青蛙”的“定期执行”功能,就可以设置工具在后台定期运行并生成XML Sitemap(同时包括图片Sitemap)。
使用“青蛙”来做竞品分析
【需求背景】
通过分析核心竞品的网站架构,我们能够快速的梳理出,自己的网站和竞品的网站在内容版块上的差距,以及竞品的内容策略(在哪个版块上投入内容资源多)。
从而有的放矢,完善自己网站的内容营销策略。
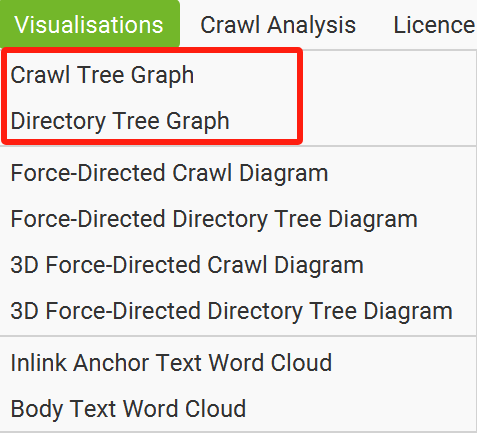
【解决办法】通过使用“青蛙”的“可视化”功能,选择不同的展示方式(树型结构展示和目录型结构展示),就能将“青蛙”抓取到的网站页面信息,以更加结构化、形象化的方式展示出来。
总的来说,“树形结构”方便我们快速了解竞品网站的“逻辑结构”,竞品最看重的页面是哪些(最短路径)。
而“目录型结构”,方便我们快速了解竞品网站的“物理结构”,竞品在内容分类上的规划是怎么样的,竞品重点投入的内容类型是什么,从而让我们去补足自身网站缺失的内容部分。
如何抓取竞品指定页面类型
【需求背景】
当我们发现竞品在某个特殊模块下(子域名或子文件夹),其内容特别多的话,就值得我们去深入分析一下。
如果竞品网站体量很大,我们并不想浪费时间抓取和筛选非必要页面时,就需要限定“青蛙”的抓取范围。
【解决办法】通过在“青蛙”的抓取配置中限制URL规则,就可以实现只抓取感兴趣的网站页面类型。
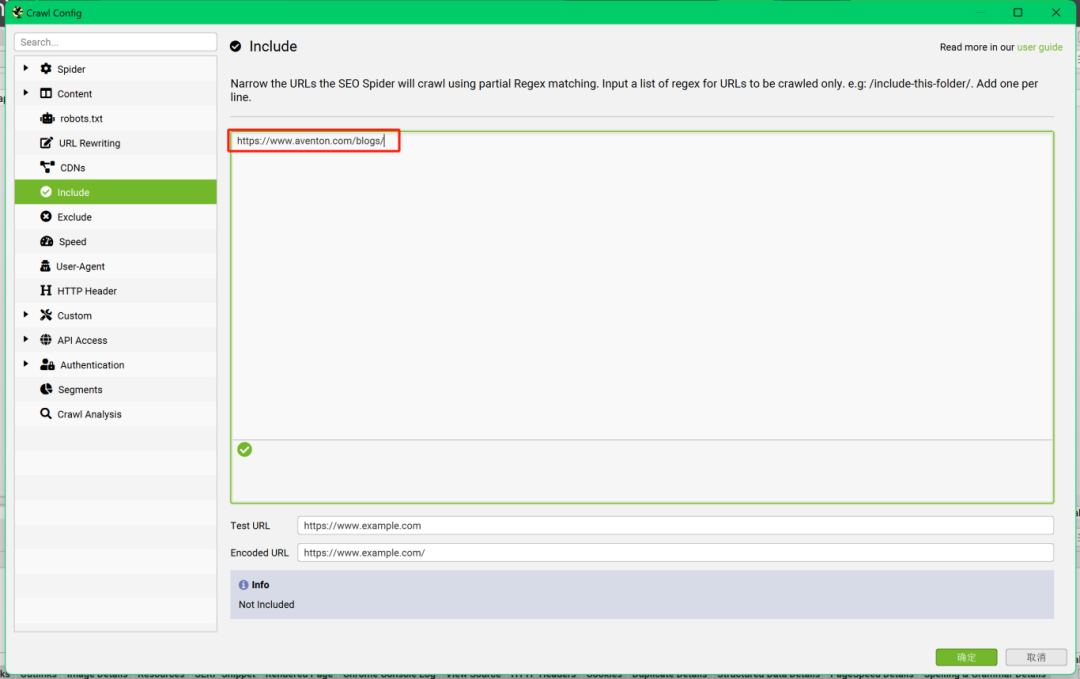
如何抓取竞品指定内容
【需求背景】
当我们需要分析竞品网站上特定位置的信息(例如产品信息,价格),来辅助优化自己的网站,或是辅助决策时,很难在市面上找到一款工具能做到,因为每个人想要抓取内容的场景非常不一样,定制化程度非常高,所以没有一款标准化产品能解决类似需求。
【解决办法】通过使用“青蛙”的“Custom Extraction”功能,在抓取规则中,填入竞品页面中想要抓取内容位置的Xpath路径,来达到批量抓取同类型页面指定位置内容的目的。
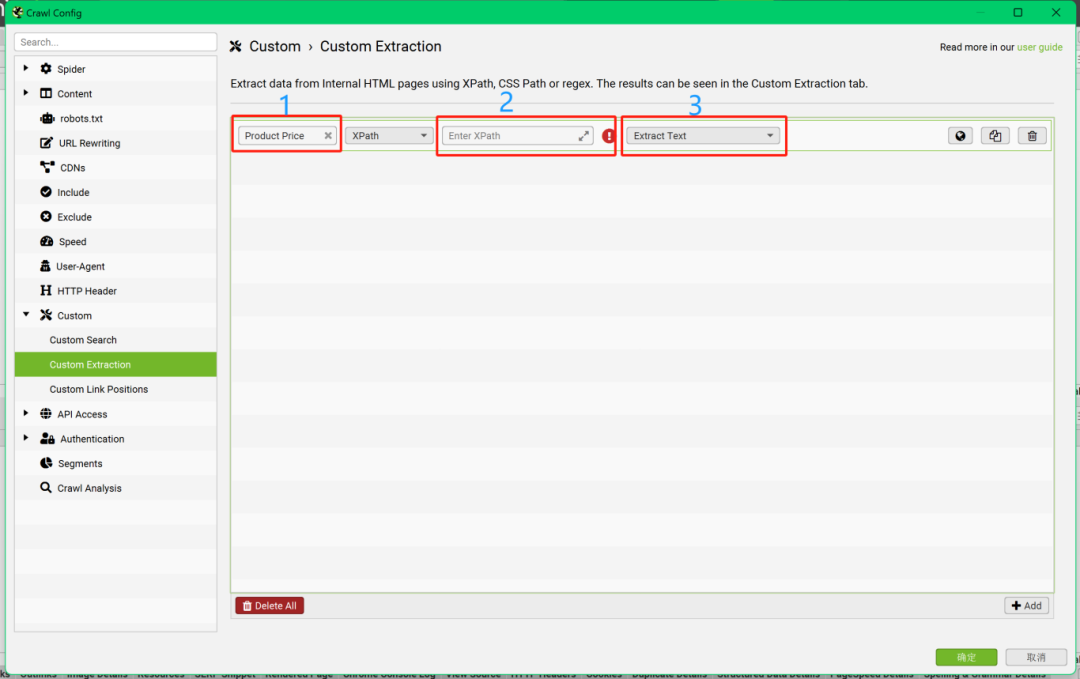
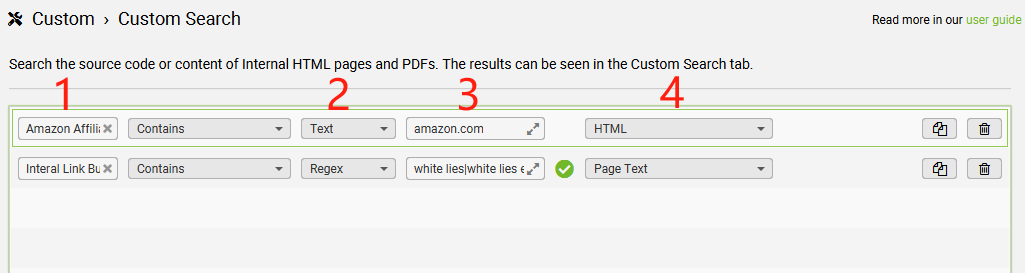
如何搜索竞品页面中的指定内容
【需求背景】
当我们想查看某网站上是否存在某Affiliate平台的链接,或者是查找是否存在为自己的某个关键词建设外链的机会,都可以通过搜索这个网站上,是否存在某个特定的文字来解决类似问题。
【解决办法】通过利用“青蛙”的“Custom Search”功能,我们可以自定义想在网站中查找的内容。
它不仅可以在页面中搜索文本,还能在HTML代码中搜索代码片段(例如链接地址)。