
 默拉智能AI系统
默拉智能AI系统
 【建站扶持计划】
【建站扶持计划】 
GPT 的三个训练阶段
“开卷有益”阶段:让GPT对海量互联网文本|做单字接龙,以扩充词汇量、语言知识、各种信息与知识。使GPT从“哑巴鹦鹉成“脑容量超级大的懂王鹦鹉”
“模板规范”阶段:让GPT对优质对话范例J做单字接龙,以规范的对话模式和对话容。使GPT变成“懂规矩的博学鹦鹉。
“创意引导”阶段:让GPT根据人类对它生成答案的好坏评分]来调节模型,以引导它生成人类认可的创意回答。使GPT变成“既懂规又会试探的博学鹦鹉!
其中第一阶段是很容易复现,然而第二阶段和第三阶段是需要大量的人工介入,包含标注人员自己的理解,人工介入的强度和时间以及工作量和质量,决定了大模型的质量和程度,这也是Openai的GPT和其他大语言模型最本质的区别!
GPT大模型存储在一个词向量的数据库,这个数据库是无法进行增删改
GPT对这个世界的认知只能停留在训练停止的那一天。因为它无法更新自己的参数来吸收新的信息。
通过训练,我们让GPT学会在一个非常巨大的磁向量空间中进行连字游戏。简单来说,用户输入一个词,AI会将这个词映射到向量空间中,并找到概率最大的词语,也就是向量空间中综合距离最近的词,然后将这些词连成句子作为回答反馈给用户。
经过几十TB的语料训练,AI在向量空间中准确地找到了每个词的位置。这些词在空间中的位置真实地映射出了语言背后的逻辑关系。如果一个足够大的向量空间可以映射出所有的逻辑语言,那么如果我们拥有一个更大的向量空间,它是否就能够映射出整个现实世界呢?这是一个有趣的问题。通过不断扩大向量空间的规模,我们可以期待AI在语言理解和创造方面取得更加卓越的成果,并为人们带来更广阔的应用前景。
让我们回顾一下什么是GPT。GPT是一个基于深度学习的模型,专门用于处理各种自然语言处理任务,如文本生成、翻译、问答等。它通过大量数据集进行预训练,学习如何理解和生成人类语言。
GPT模型之所以强大,部分原因在于其庞大的参数数量。这些参数可以想象成GPT的大脑中的神经连接,每个连接都存储着特定的信息,负责特定的任务。训练过程中,这些参数不断调整,直到找到最佳的组合方式,使得模型可以准确地完成任务。
现在,重点来了。一旦GPT的训练完成,它的向量空间——也就是所有这些参数构成的数学空间——就固定下来了。你可以把这个向量空间想象成一个庞大的多维空间,其中每一个维度代表了模型可以调用的一种特性或概念。固定下来的向量空间意味着GPT不会根据与它的交互来改变这些参数。这是由于调整这些参数需要巨量的计算资源。
要训练GPT,我们需要使用大量的显卡和机器,这些硬件需连续工作数日,甚至数周才能完成训练。这是一个极其耗费资源的过程。显然,每当与GPT交互时,都进行一次这样的训练是不可行的。
这就是为什么说GPT以不变应万变。无论你问它什么问题,它都会在这个固定的向量空间中搜索答案。但是,答案的组织方式是动态的,它会根据你提出的问题来串联出不同的路径。因此,尽管GPT的“思考”模式是静态的,它仍然能够给你一种它真的在与你互动的错觉。
这就带来了一个有趣的现象:GPT对这个世界的认知只能停留在训练停止的那一天。因为它无法更新自己的参数来吸收新的信息,它不会随着时间的推移而学习或记住新的事物。它无法产生新的记忆或经验,这意味着如果世界发生了改变,而GPT没有经过重新训练来吸收这些变化,它的输出可能会变得过时或不准确。
这个局限性对于我们使用和理解GPT模型时非常重要。虽然它能够产生出色的语言模式,但我们不能期望它完全理解现实世界中的最新发展或事件。例如,如果你问GPT关于最近的新闻事件或流行文化的趋势,它能够提供的信息可能是基于它停止训练时的数据集,而不是最新的信息。
然而,即便如此,GPT的功能仍然非常强大。它能够帮助我们自动化许多语言相关的任务,比如草稿撰写、初步的内容创作、甚至是编程代码的辅助。对于内容创作者而言,GPT可以成为一个非常有价值的工具,它可以帮助节省时间,激发创意,并在某些情况下,提供灵感和框架,让创作者可以在此基础上进一步发展和完善!
我们再学习一下token这个概念
在GPT的技术枢纽中,"Token"是不可或缺的基石。Token代表文本片段的原子级单位,它们可以是单词、短语或任何具有独立意义的字符组合。当用户与GPT互动时,这个智能系统会将输入的文本拆分成一个个Token,并以此作为构建回应的基础。在自然语言处理(NLP)的领域里,Token不仅仅是一个术语,它承载着文本中被认为是独立元素的各个部分,比如单词、数字或符号。
以“我爱北京天安门”为例,每个字“我”、“爱”、“北京”、“天安门”均可被视为一个独立的Token。在NLP的数据预处理过程中,Token化是至关重要的一环,因为它助力模型对文本进行精准解读和分析。而Token本身也有多种类别,每一类都与特定的文本元素相对应:
- 词汇Token(Word Tokens):这类Token普遍存在于文本中,代表着词汇,例如“猫”、“跑”等。
- 符号Token(Symbol Tokens):涵盖了各种标点符号和特殊字符,包括逗号、问号等。
- 数字Token(Number Tokens):专指数字,如“2023”、“100”等。
每一种Token在文本处理中都发挥着其独特的功能:
- 词汇Token有助于模型把握文本的语义层面;
- 符号Token则在解析文本结构和语法方面扮演关键角色;
- 数字Token在处理含有数值信息的文本时尤其关键。
通过对文本进行精细的Token切割,NLP模型如ChatGPT就能够更加准确地解析和理解人类语言,进而在回答问题、生成文本或执行其他与语言相关的任务时,展现出更佳的性能和准确度。
大语言模型LLM,从8K到32K模型,需要消耗的资源是指数级上升
GPT-4的技术进步带来了一个引人瞩目的变化:它的上下文处理能力从原先的8千个Token跃升至32千个Token。让我们通过一个简单的比喻来深入理解,为什么管理更多Token的模型(比如32千Token)会比较少Token(例如8千Token)的模型复杂得多。
在AI技术领域,这样的“交流互动”是通过Transformer算法中的"注意力机制"(attention mechanism)来完成的。在这个机制中,每个Token都要与其他所有Token进行相互计算。因此,随着Token数量的增加,所需的计算量会急剧上升,呈现平方级增长。例如,8千Token的情况下大约需要进行6,400万次(8,000 x 8,000)计算,而32千Token则需执行高达102亿次(32,000 x 32,000)计算。这不仅解释了为什么处理32千Token的模型难度如此之大,也预示着处理更大规模Token,比如128千Token,将是一项更为艰巨的任务。
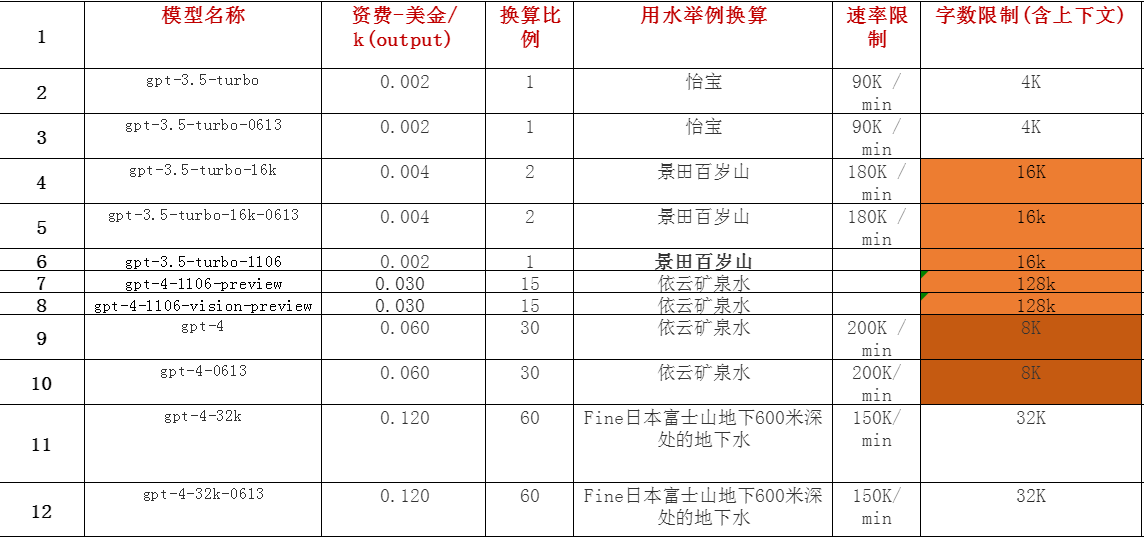
Openai的不同模型的定价也是成倍上涨!
回到标题那么复现一个gpt4 LLM有多难呢?
gpt-4-vision-preview大模型增加了识图功能,
GPT 4.0-1.8w亿参数中,有大量的图片参数,训练一次的成本极高。

全世界独一份的openai的GPT大模型生态!
从时间成本到技术成本以及运营成本上,可以说是非常难。
从经济角度考虑,更是没有必要重复造轮子了!你觉得呢 ?





