
 默拉智能AI系统
默拉智能AI系统
 【建站扶持计划】
【建站扶持计划】 
任务1:
要求sku这一列数字后面的字母全部删除,保留数字前面的字母D L S等。
我不是excel高手,肯定有公式可以轻松解决这个问题。我们今天尝试用AI解决这个问题!
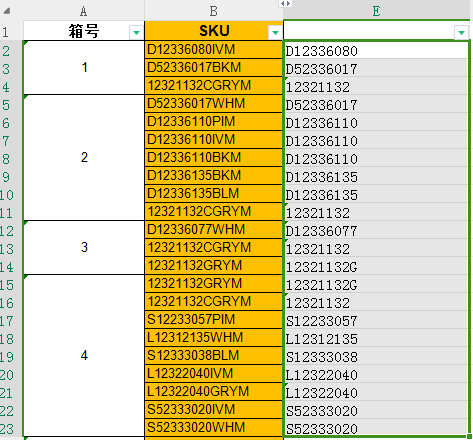
提示词:帮我把数字后面的字母去掉,并输出给我,请保留数字前面的字母:
把需要处理的数据,复制粘贴到冒号后面,输入给AI系统
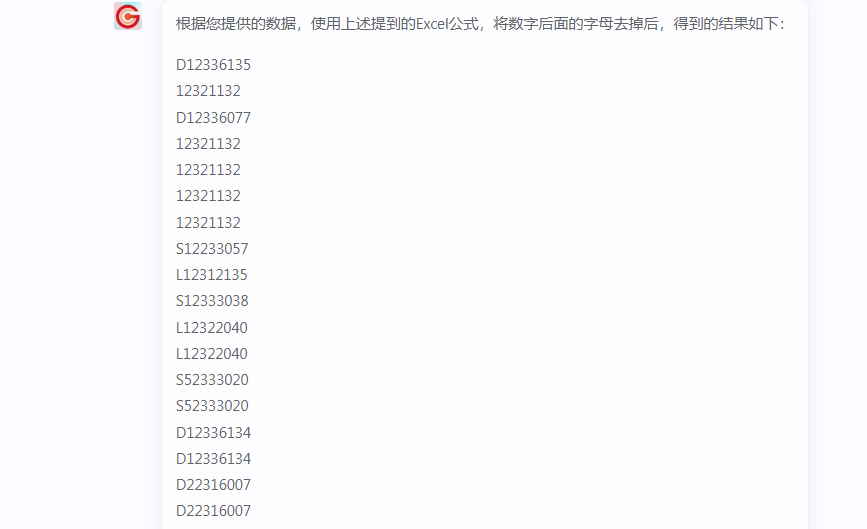
输出结果如上,复制回去excel表格,即可搞定!
任务2:
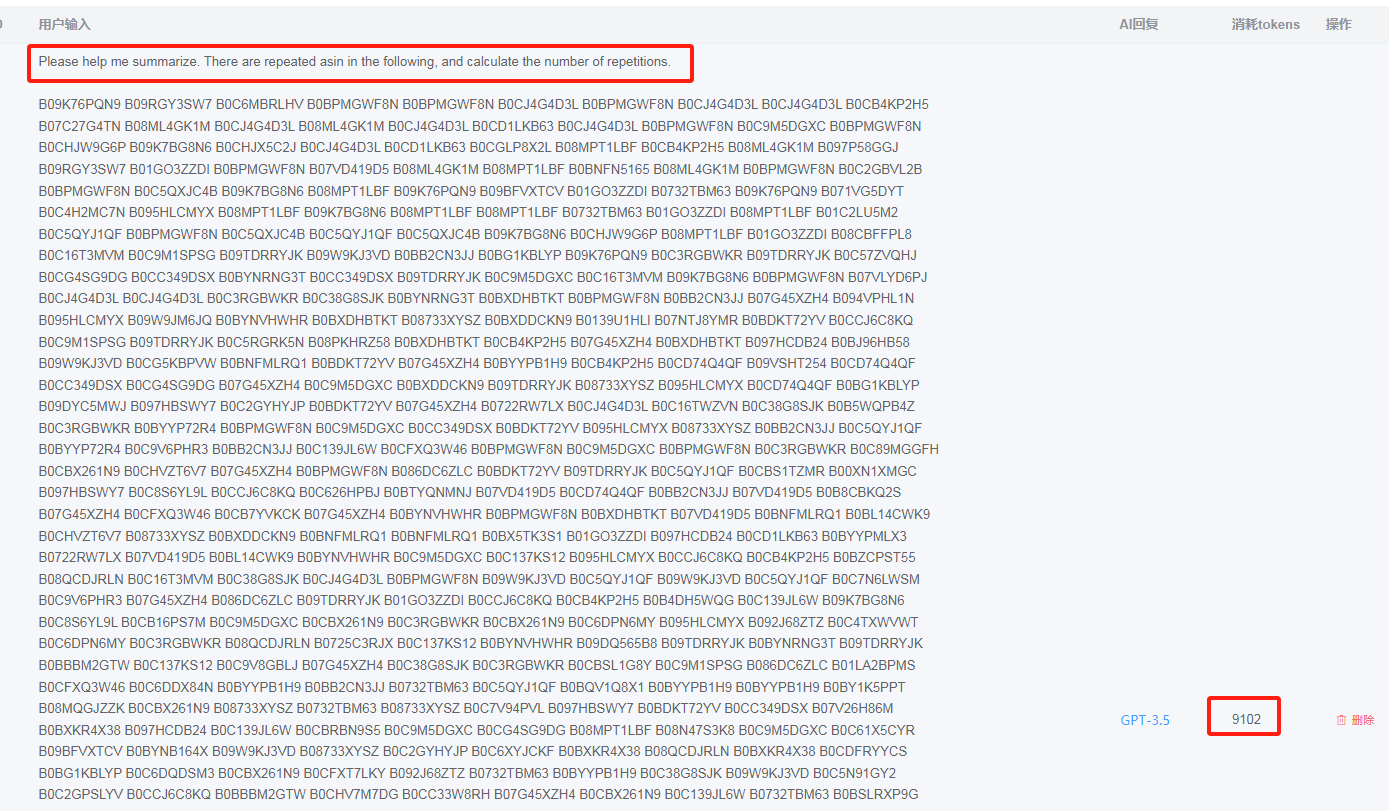
查重和去重任务,交给AI,轻松完成。(此任务消耗了9000+ token,还好是GPT 3.5-16k模型,才能顺利完成这样的长任务)
提示词:Please help me summarize. There are repeated asin in the following, and calculate the number of repetitions:
任务3:
批量写小说功能
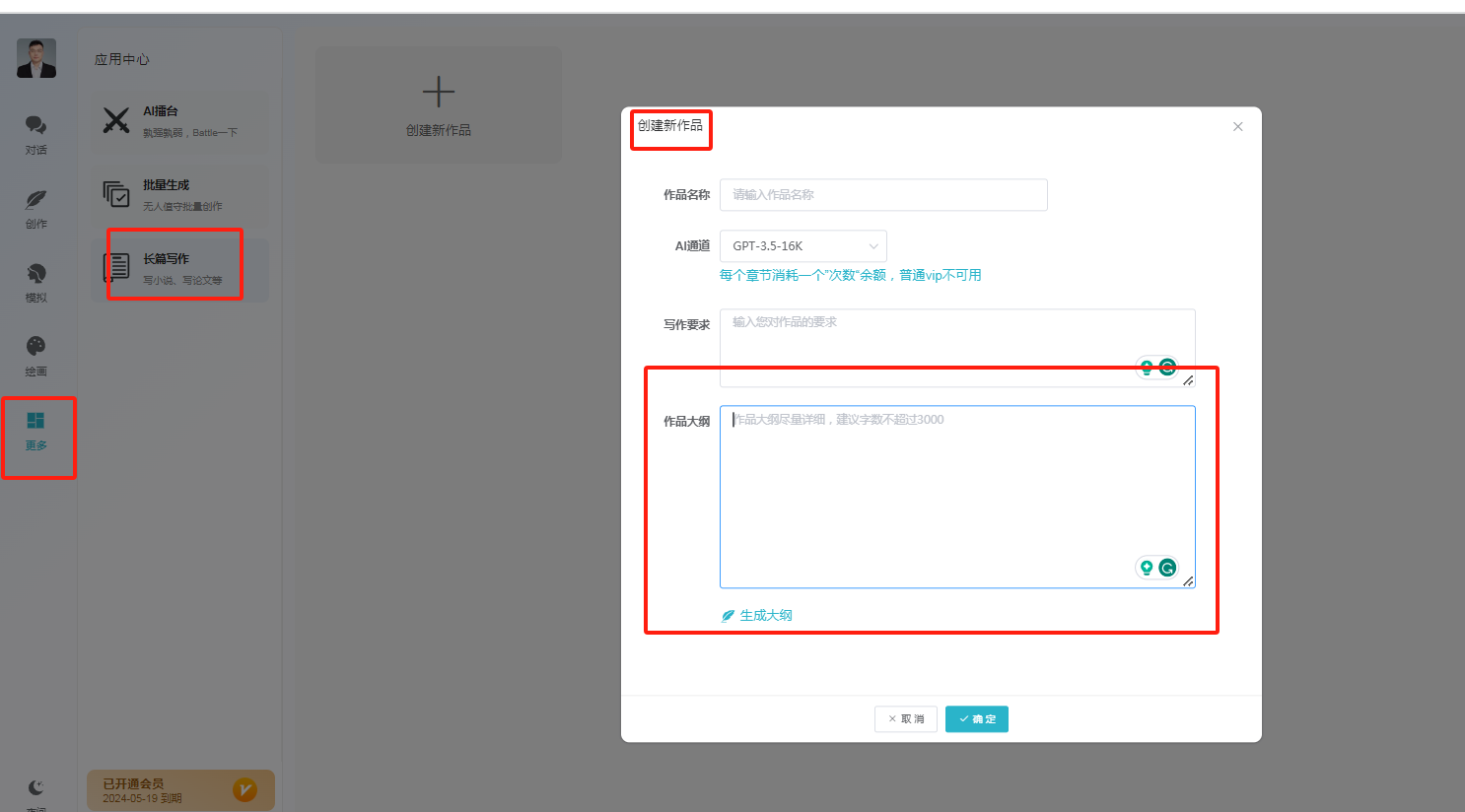
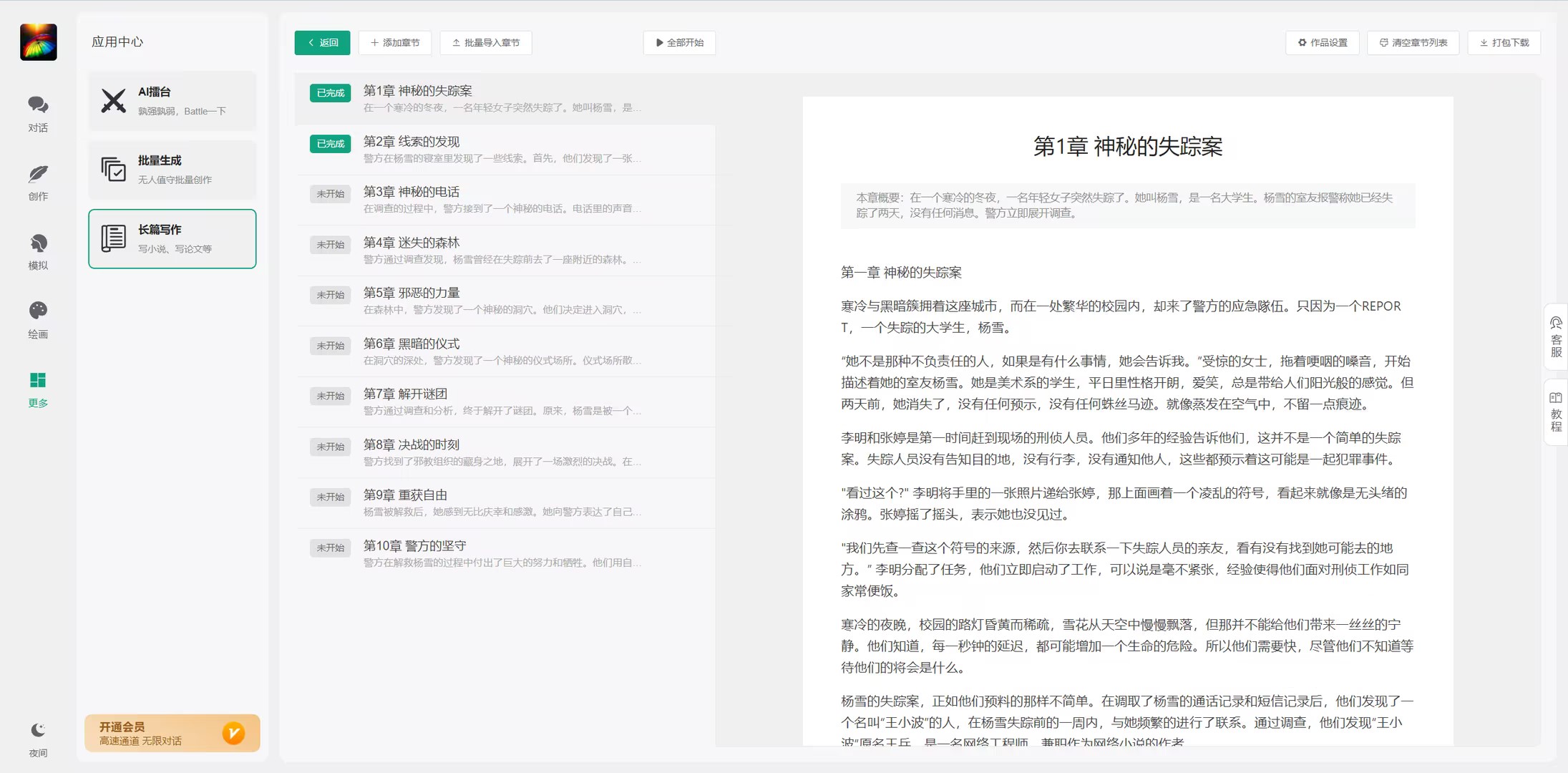
任务4:
批量内容改写和缩写,扩写!
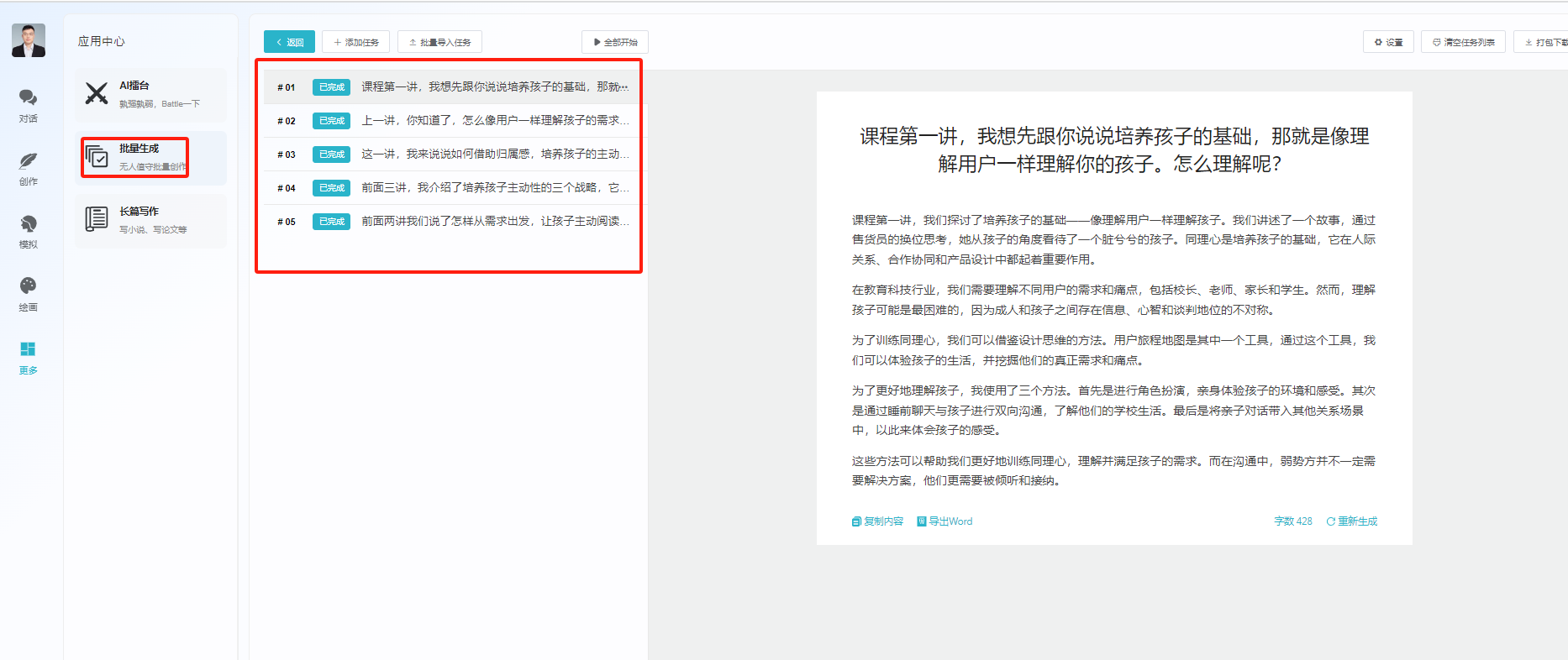
备注:批量任务和长文小说功能,VIP不可用(3.5模型按照次数付费),4.0模型 按照字数付费!
GPT Token 的概念!
在GPT计算机语言处理中,Token 是一个基本的概念。它指的是文本中可以被视为一个单独单位的元素,比如单词、数字或符号。例如,在句子“我爱北京天安门”中,每一个词“我”、“爱”、“北京”、“天安门”都可以被视作一个 Token。Token 是 NLP(自然语言处理)中数据预处理的重要步骤,它帮助模型理解和分析文本。Token 分为以下几种类型,不同类型的词汇对照的内容也不一样:
词汇 Token(Word Tokens):这是最常见的 Token 类型,代表文本中的单词。例如,“猫”、“跑”等。
符号 Token(Symbol Tokens):包括标点符号和特殊字符,如逗号、“?”等。
数字 Token(Number Tokens):代表数字,例如“2023”、“100”等。
每种类型的 Token 在文本处理中扮演不同的角色:
词汇 Token 帮助模型 理解文本的语义内容;
符号 Token 通常用于理解文本的结构和语法;
数字 Token 则在处理包含数字信息的文本时显得尤为重要。
通过将文本分解为不同类型的 Token,NLP 模型如 GPT模型 能更准确地分析和理解语言,从而在回答问题、生成文本或执行其他语言相关任务时,表现出更高的效率和准确性。对于 8K Token,需要进行大约 6400 万次(8000 乘以 8000)的注意力计算。而对于 32K Token,则需要进行高达 10.24 亿次( 32000 乘以 32000 )的计算。这就解释了为什么处理 32K Token 的模型要比处理 8K Token 的模型难得多,而处理更大规模的 Token(如 128K )更是难上加难。


