
想用更少的参数,实现更强的视觉模型性能?上海大学提出的ECViT提供了一个新思路。它仅凭4.8M参数量,就在图像分类任务上全面超越了传统的ViT、ResNet和ConvNeXt。
其成功关键在于多尺度卷积与注意力机制的协同设计。卷积高效提取局部特征,注意力建立全局依赖,二者结合让模型无需大规模预训练就拥有了出色的效率和泛化能力。这一架构极具通用性,可广泛应用于分类、检测、分割等各类视觉任务。
为助力你的研究,我们精选了17篇相关前沿论文,为你提供扎实的baseline参考。如果你正在寻找轻量化、高效率的CV研究方向,这份资源不容错过。


论文一:MATCNN: Infrared and Visible Image Fusion Method Based on Multi-scale CNN with Attention Transformer
关键词: 图像融合, CNN-Transformer混合架构, 多尺度特征, 显著性掩膜, 全局特征提取
研究方法:
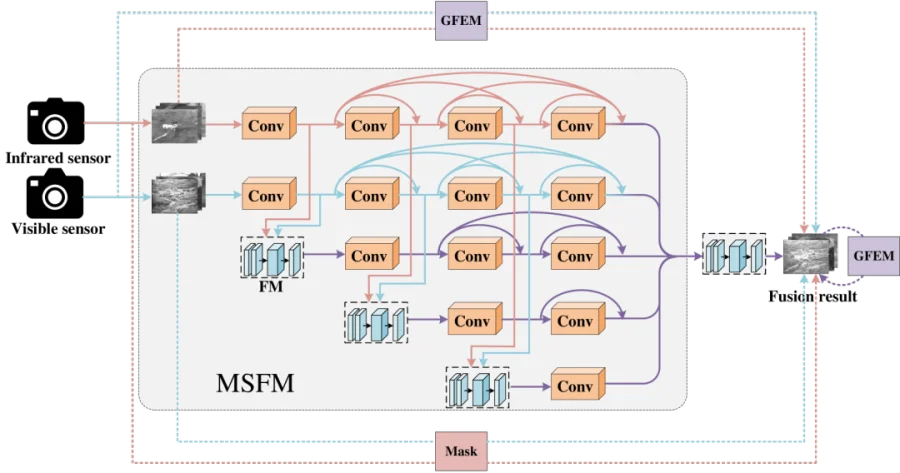
针对现有融合方法在“保留红外热目标”和“维持可见光纹理”之间难以平衡的问题,论文提出了一种名为 MATCNN 的新型混合架构。该模型由两部分核心组成:多尺度融合模块 (MSFM)和 全局特征提取模块 (GFEM)。MSFM 利用伪孪生CNN网络提取不同尺度的局部细节特征,防止纹理丢失;而GFEM 则基于 Swin Transformer 结构,负责在四个尺度上捕捉长距离的全局语义信息。此外,为了防止关键信息在融合中被淹没,作者不仅引入了显著性信息掩膜(Mask)来标记红外高亮区域,还设计了一套包含内容损失、结构相似性损失和全局特征损失的联合优化算法,确保融合图像既有“热度”又有“清晰度”。
论文创新点:
-
构建了MSFM(局部)与 GFEM(全局)并行的混合架构,实现了在保留丰富可见光背景纹理的同时,大幅增强了红外目标的显著性。 -
创新地引入了针对红外图像的显著性信息掩膜(Mask),解决了传统融合方法容易导致红外热目标亮度衰减和边缘模糊的关键痛点。 -
通过结合L1范数构建的新型全局特征损失函数,将融合图像与源图像在多尺度下的全局像素活跃度差异降至最低,增强了特征连续性。 -
首次将内容损失、SSIM结构损失与掩膜引导机制深度结合,验证了在TNO、MSRS等数据集上,该方法在对比度(SD)和视觉保真度(VIF)指标上均优于SwinFusion等SOTA方法。

论文链接: https://arxiv.org/abs/2502.01959v1

论文二:ECViT: Efficient Convolutional Vision Transformer with Local-Attention and Multi-scale Stages
关键词: 高效ViT, 卷积神经网络, 局部注意力, 特征金字塔, 轻量级模型
研究方法:
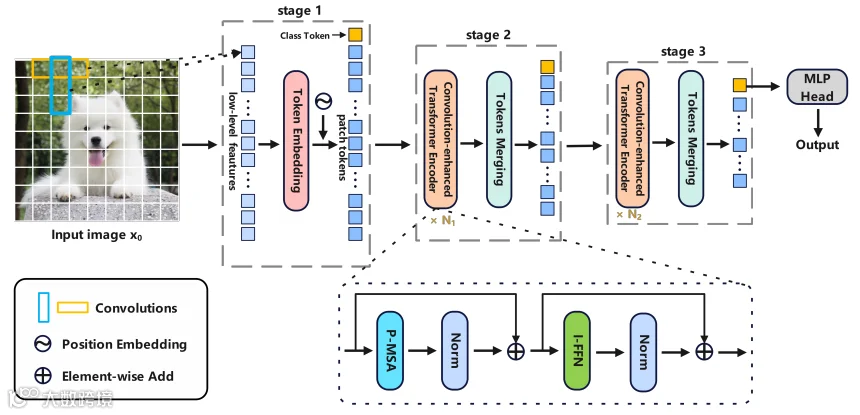
针对标准 Vision Transformer 计算复杂度高且缺乏局部感知能力的问题,论文提出了一种轻量级混合模型 ECViT。该模型旨在引入 CNN 的固有优势(如平移不变性和局部性)来改造 Transformer。首先,ECViT 摒弃了直接切片(Patch)的方式,改用卷积网络进行图像Tokenizer化,以提取更丰富的底层特征。在编码器阶段,设计了 分区多头自注意力 (P-MSA) 来降低计算量,并使用 交互式前馈网络 (I-FFN) 替代传统 MLP,通过深度卷积增强相邻Token的空间交互。整体架构采用金字塔结构(Pyramid Structure),通过 Token Merging 层逐步降低序列长度并增加维度,实现高效的多尺度特征提取。
论文创新点:
-
提出/构建了基于卷积特征提取的 Tokenizer 和多阶段金字塔架构,实现了在无预训练情况下对小数据集(如CIFAR10)的高效学习能力。 -
创新地设计了分区多头自注意力(P-MSA)机制,解决了全局自注意力计算复杂度呈二次方增长的瓶颈,同时通过Class Token聚合局部信息。 -
通过在FFN中引入深度可分离卷积(I-FFN),将模型的参数量压缩至4.8M左右,同时计算量仅为0.698G FLOPs。 -
将ECViT与ResNet18及ViT-Tiny进行对比,验证了其在CIFAR10上达到91.03%的准确率(比ViT-Tiny高出近15%),实现了性能与效率的最佳平衡。

论文链接: https://arxiv.org/abs/2504.14825v1
